Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Parallel computing (điện toán song song)
- Tính thời sự: Tháng 3/2023.
- Thời gian đọc: 7 phút, lồng vào thời gian uống cà phê (uống cà phê xong là đọc xong).
-
Ⓐ. Đề dẫn.
Chủ đề lần này là GPU (Graphics Processing Unit). Thoạt nghe chúng ta dễ có cảm giác như đang nói về vấn đề thiết bị điện tử (electronic device). Lúc đầu đúng thế thật. Về sau thiết bị phần cứng này được “mềm hóa” thành bộ xử lý (Processing Unit).
Tôi tin rằng trên diễn đàn này có nhiều anh/chị đã từng mày mò với các chip điện tử dòng thời xưa 8 bit như Intel 8085, Zilog Z80, … Rồi sau đó chuyển sang dòng 16 bit như Intel 8086, Intel 80286, rồi 32 bit như i386, … rồi 64 bit như x86-64. Tuy các bộ xử lý trung tâm CPU (Central Processing Unit) về sau càng ngày càng nhanh nhưng chúng xử lý một cách tuần tự. Điều này thì tôi tin anh/chị chẳng có gì ngạc nhiên. Để xử lý đa luồng (multi-thread), đa nhiệm (multi-task) thì chúng ta cho các chương trình (program) “nằm” trong bộ nhớ RAM rồi CPU chạy vòng tròn xử lý từng “khúc” một của từng luồng (thread), từng nhiệm (task). Người dùng có cảm giác như CPU xử lý đồng thời, nhưng bản chất không phải thế. Chỉ là CPU xử lý rất nhanh, quay vòng liên tục, nhanh đến mức con người không “thấy” được.
Lại nói về việc hiển thị lên màn hình. Hồi xưa chúng ta xem việc hiển thị lên màn hình là điền vào một ma trận W x H điểm (pixel), trong đó W là chiều rộng, H là chiều cao. Việc hiển thị thực sự là việc của card màn hình (graphics card): căn cứ vào ma trận điểm này, card màn hình “bắn” các điểm tương ứng lên màn hiển thị. Ví dụ, máy IBM PC hồi xưa có card VGA với độ phân giải 640 x 480 hay card SVGA có độ phân giải 800 x 600. Thực chất card màn hình là một tấm mạch tích hợp (integrated circuit), cắm vào khe PCI nối với bo mạch chính. Chính PCI này là bus kết nối CPU với card màn hình. Chúng ta tưởng tượng PCI chính là chiếc cầu để chuyển dữ liệu từ bộ nhớ RAM vào bộ nhớ của card màn hình (gọi là Video RAM hay VRAM).
Bây giờ chúng ta lại nói đến việc xử lý từng điểm của ma trận màn hình. Các điểm trên màn hình hoàn toàn độc lập với nhau. Việc xử lý điểm này hoàn toàn không làm ảnh hưởng đến xử lý các điểm khác. Nếu có cách nào đó xử lý đồng thời tất cả các điểm cùng lúc thì màn hình sẽ hiển thị nhanh hơn. Nó cũng không phụ thuộc vào độ phân giải của màn hình. Độ phân giải cao hoặc độ phân giải thấp đều có thời gian xử lý như nhau vì card màn hình bắn các điểm VRAM lên màn hình bằng mạch tích hợp.
Nói thêm, trong đồ họa máy tính, người ta có một loại phần mềm có tên gọi là shader (tô bóng). Phần mềm này tạo đồ họa 3 chiều: tính độ sáng (light), độ tối (darkness) và màu (color) của từng điểm. Đối với các điểm thuộc dạng này, người ta cần xử lý sơ bộ trước khi “bắn” lên màn hình. Từ đặc điểm này, người ta nghĩ đến việc lập trình phần tô bóng ngay trên card đồ họa. Muốn lập trình được, card đồ họa cần bộ xử lý (processor), thanh ghi (register), bộ nhớ (RAM), bộ tính toán (floating point), gần giống với CPU nhưng chỉ để xử lý đồ họa. Từ đó, ra đời GPU (Graphics Processing Unit) – bộ xử lý đồ họa.
-
Người ta nhận thấy có một vài điểm đặc biệt của GPU:
- Dữ liệu mà GPU xử lý là ma trận – nói một cách tổng quát là mảng. Các phần tử của mảng giống nhau về cấu trúc và độc lập lẫn nhau;
- Có thể áp phép toán (như tô bóng) lên tất cả các phần tử của mảng một cách đồng thời;
Với đặc điểm trên thì GPU có thể xử lý song song toàn bộ các phần tử của mảng. Người ta gọi phương thức xử lý này là SIMD (Single Instruction, Multiple Data): lệnh đơn, nhiều dữ liệu (xem hình vẽ).
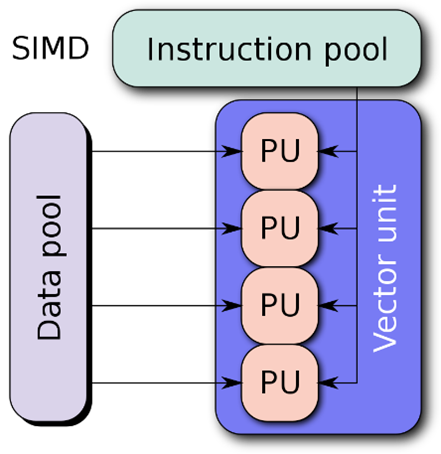
Nguồn.
Người ta gọi mảng các bản ghi dữ liệu như trên là Stream, phép toán là Kernel. Chúng ta có thể coi Kernel là một hàm.
Chú ý rằng nếu so về tốc độ tính toán thì GPU chậm hơn CPU. Tốc độ của GPU dao động từ 500 đến 800 MHz. Nghĩa là GPU có thể xử lý 500 triệu đến 800 triệu lệnh/giây. Tốc độ của CPU có thể đạt từ 3.5 đến 4 GHz. Nghĩa là CPU có thể xử lý đến 4 tỷ lệnh/giây. Như vậy tốc độ CPU nhanh hơn GPU (4 tỷ / 500 triệu) ~ 8 lần. GPU chỉ có ưu điểm là xử lý song song: áp hàm Kernel đồng thời lên toàn bộ mảng Stream.
-
Ⓑ. GPU xử lý song song bằng cách nào?
Côt lõi vấn đề: GPU có hàng ngàn core (lõi) trong lúc CPU thường chỉ có 1 core hoặc cùng lắm là hàng chục core. Mỗi một core của GPU lại có thể chạy hàng ngàn thread (luồng). Tổng thể là GPU cùng lúc xử lý hàng triệu thread và mỗi một thread chỉ xử lý một đoạn trong mảng dữ liệu Stream. Xin lấy một ví dụ.
Giả thiết chúng ta có một ảnh 1920x1080 pixel (= 2,073,600 pixel) và chúng ta cần tô bóng cho tất cả các pixel.
Chương trình chạy trên CPU xử lý bằng cách nào? Chúng ta sẽ lập 2 vòng lặp lồng nhau và tô bóng từng điểm một và số lượng phép toán cần xử lý là 2,073,600. Chú ý rằng thuật toán tô bóng giống nhau, chỉ có tham số tô bóng (pixel) khác nhau mà thôi. Đương nhiên cách xử lý này chậm.
Thế còn GPU xử lý như thế nào? Vì GPU sẽ phát sinh ra 2,073,600 thread, mỗi một thread gọi hàm tô bóng với pixel được chỉ định cho chính thread đó. Có thể nói GPU xử lý đồng thời 2,073,600 hàm tô bóng cùng một lúc. Thú vị nhất là thời gian xử lý của GPU không phụ thuộc vào kích thước ảnh vì tất cả các điểm cần tô bóng được xử lý đồng thời.
Chú ý: Tốc độ xử lý của GPU = [clock speed] x [số lượng core] (chứ không phải [clock speed] x [số lượng thread]). Số thread sinh ra từ 1 core thực ra là xử lý tuần tự từ core đấy.
-
Ⓒ. Làm thế nào để chạy chương trình trên GPU?
Trả lời cô đọng:
Thông qua giao diện lập trình (API) CUDA (Compute Unified Device Architecture).
-
Trả lời chi tiết:
Bây giờ chúng ta xét đến mối quan hệ giữa CPU và GPU. Trong mối quan hệ này, vai của CPU là chủ (host) và vai của GPU là thiết bị (device) – xem hình vẽ.

Nguồn
Trong hình vẽ trên, chương trình chính chạy trên CPU. CPU phối hợp với GPU như sau:
- Chương trình chính chép dữ liệu từ bộ nhớ của CPU sang bộ nhớ của GPU
- Chương trình chính kích hoạt GPU
- GPU xử lý song song bằng cách áp Kernel lên toàn bộ mảng dữ liệu vừa chép vào
- GPU chép kết quả từ bộ nhớ của GPU sang bộ nhớ của CPU.
CUDA được tích hợp vào các ngôn ngữ lập trình như C, C++, Fortran, Python và các framework như TensorFlow, PyTorch, … Dưới góc độ của người lập trình thì chúng ta chỉ cần hiểu nguyên lý như trên. Việc còn lại chỉ là gọi các hàm từ các thư viện có sẵn.
-
Ⓓ. Trải nghiệm so sánh CPU và GPU.
Anh/chị có thể chất vấn: lý thuyết ai chả biết, nhưng làm thế nào để “kiểm tra” xem CPU và GPU chạy nhanh chậm thế nào. Phần này tôi xin giới thiệu với anh/chị cách thử và so sánh thời gian xử lý của CPU và GPU ngay trên chính PC của anh/chị.
💡 Ý tưởng là trên cùng phép toán, chúng ta thử tính thời gian xử lý phép toán đó của CPU và thời gian xử lý cũng cùng phép toán đó của GPU. Tôi chọn 2 phép toán để so sánh:
- Phép toán 1: nhân 2 số vô hướng với nhau
- Phép toán 2: nhân 2 ma trận với nhau – mỗi ma trận có 10,000 dòng, 10,000 cột (là ma trận có 100 triệu số thực). Ma trận này được khởi tạo bởi một hàm ngẫu nhiên.
Công cụ mà tôi sử dụng là google colab notebook (đặt tên file là “CPU, GPU comparison.ipynb”). Trong file này tôi sử dụng ngôn ngữ lập trình Python trên nền framework PyTorch. Anh/chị nào có nhã ý tìm hiểu chi tiết xin mời anh/chị tham khảo phần Phụ lục.
▼ Giải thích ý tưởng
Tôi chia phần chương trình thành 2 đoạn: đoạn đầu do CPU xử lý và đoạn sau do GPU xử lý. Tôi đánh số các Cell để anh/chị tiện theo dõi. Trong mỗi Cell, ngay dòng lệnh đầu tiên tôi sử dụng hàm %%timeit để đo thời gian xử lý của cả Cell. Anh/chị nào tò mò về lập trình của %%timeit xin tham khảo ở đây.
- Cell[1], Cell[2], Cell[3] do CPU xử lý.
- Cell[4], Cell[5], Cell[6], Cell[7] do GPU xử lý
-
CPU
Cell [1]: import framework PyTorch
Cell [2]: Đo thời gian xử lý nhân 2 số với nhau (thực chất là nhân 2 ma trận (1,1) với nhau). Thời gian CPU xử lý mất khoảng 8.38 micro giây.
Cell [3]: Đo thời gian xử lý nhân 2 ma trận (10000, 10000) với nhau. Thời gian CPU xử lý mất khoảng 32.7 giây (hơn nửa phút).
-
GPU
Trước khi xử lý, chuyển sang chế độ chạy bằng GPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn GPU
Cell[4]: import framework PyTorch
Cell[5]: chọn device là CUDA
Cell[6]: Đo thời gian xử lý nhân 2 số với nhau (thực chất là nhân 2 ma trận [1,1] với nhau). Thời gian GPU xử lý mất khoảng 73.6 micro giây (so với CPU chỉ mất 8.38 micro giây).
Cell[7]: Đo thời gian xử lý nhân 2 ma trận (10000, 10000) với nhau. Thời gian GPU xử lý mất khoảng 988 mili giây (chưa đầy 1 giây) so với CPU xử lý mất 32.7 giây.
▲ Giải thích
-
Ⓔ. Suy ngẫm chậm.
Đôi lúc, công nghệ mới ra đời một cách ngẫu nhiên thú vị. Có lẽ sự ra đời của GPU nằm trong số đó. Xuất phát từ một ý tưởng ban đầu là tăng tốc xử lý các điểm ảnh trên màn hình (dùng trong các phần mềm games, video), dần dần các nhà công nghệ đã phát triển các bộ xử lý GPU đa nhân (multi-core), mỗi một core chịu trác nhiệm xử lý một vùng điểm trên màn hình. Vì vậy việc tăng tốc xử lý màn hình đồng nghĩa với thiết kế chip GPU tăng số core. Người ta nhận thấy số core trong một chip GPU tăng theo cấp số nhân hàng năm. Khác với quy luật Moore (Moore’s Law: số lượng bóng bán dẫn trên một chip liên tục tăng gấp đôi trong chu kỳ từ 18 đến 24 tháng) đang tiến dần đến giới hạn thì việc tăng số core trong GPU có cảm giác như chỉ mới bắt đầu và chưa thấy giới hạn trong tương lai gần.
Tất nhiên chúng ta hiểu rằng GPU đóng góp vào dòng chảy chung của điện toán song song (parallel computing) như điện toán đa nhân (multi-core computing), điện toán phân tán (distributed computing), điện toán cụm (cluster computing), điện toán lưới (grid computing), …
Tuy nhiên, GPU có một điểm rất thú vị: phần cứng của GPU phát triển gắn liền với phần mềm, đặc biệt gắn liền với Machine Learning. Vì sao vậy? Nếu chúng ta soi các phép toán của mạng nơ-ron (Neural Network) thì việc tính toán tại các nút đơn thuần là nhân ma trận (xem hình vẽ). Việc tính toán cả ở chiều xuôi (feedforward) và chiều ngược (backpropagation) đều là các phép nhân ma trận. Hiển nhiên, phép nhân ma trận chẳng có gì là bí hiểm cả (tổ hợp phép nhân và phép cộng của các số vô hướng). Chỉ có một nhược điểm là mất nhiều thời gian để tính toán. Cái mà người ta có ý tưởng tăng tốc phép nhân ma trận là họ “cứng hóa” phép toán này: sản xuất chip GPU với nhiều Tensor core. (Tensor là một cách gọi mỹ miều của mảng dữ liệu N chiều.) Với Tensor core thì phép nhân ma trận được thực hiện chỉ trong vài nhịp đồng hồ máy thay vì phải hàng trăm, hàng ngàn nhịp. Nvidia là công ty sản xuất chip GPU với nhiều Tensor core. (Nhân tiện thông tin thêm: tính đến tháng 3/2023, Nvidia chiếm 84% thị phần GPU, AMD 12%, trong lúc Intel chỉ chiếm 4%.)
Cùng ý tưởng như Tensor core, Google sản xuất chip TPU (TensorFlow Processing Unit). Chỉ có điều là TPU chỉ dùng trong các ứng dụng của chính Google, họ không bán chip này ra thị trường. Google cung cấp dịch vụ điện toán đám mây có TPU. Thuê bao có thể huấn luyện các mô hình chạy trên đám mây của Google mà không cần phải mua sắm thiết bị.
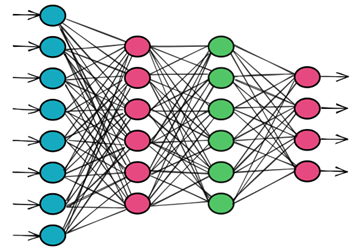
Ví dụ về một mạng nơ-ron (Neural Network).
-
Có thể nói xu thế phát triển phần cứng đang dần gắn liền với phát triển phần mềm, phần cứng có chỗ được “mềm hóa” và phần mềm có một số phép toán được “cứng hóa”.
-
Trước khi kết thúc bài post, tôi trân trọng mời anh/chị một tách cà phê với họa tiết nền GPU.
Credit: Bing Image Creator, powered by DALL·E.

-
Ⓕ. Phụ lục: Nội dung file “CPU, GPU comparison.ipynb”
CPU
[1] import torch
---
[2] %%timeit
z = torch.randn(1,1)
result = torch.matmul(z,z)
del z, result
-
8.38 µs ± 1.63 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each)
---
[3] %%timeit
z = torch.randn(10000,10000)
result = torch.matmul(z,z)
del z, result
-
32.7 s ± 320 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
GPU
Trước khi xử lý, chuyển sang chế độ chạy bằng GPU. Cách chuyển như sau:
- Click menu Runtime
- Chọn Change Runtime Type
- Chọn GPU
[4] import torch
---
[5] device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
---
[6] %%timeit
z = torch.randn(1,1).to(device)
result = torch.matmul(z,z)
del z, result
-
The slowest run took 5.38 times longer than the fastest. This could mean that an intermediate result is being cached.
73.6 µs ± 63.2 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
---
[7] %%timeit
z = torch.randn(10000,10000).to(device)
result = torch.matmul(z,z)
del z, result
-
988 ms ± 193 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
