Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Machine Learning
- Tính thời sự: Tháng 8/2023.
- Thời gian đọc: 10 phút, lồng vào thời gian uống cà phê (uống cà phê xong là đọc xong).
-
Ⓐ. Đề dẫn.
Chủ đề lần này tôi để là Image Segmentation (Wikipedia dịch là “phân vùng ảnh”). Bản thân chủ đề này rộng nên tôi khoanh vùng phần đàm luận chỉ gói gọn trong khuôn khổ bài báo của Meta AI là Segment Anything, đăng vào tháng 4/2023. Lý do cho sự lựa chọn này: bài báo vừa có phần nghiên cứu lý thuyết, vừa có phần mềm cho phép người đọc có thể thử và trải nghiệm. Đặc biệt, họ mở toàn bộ nguồn và dữ liệu. Các bài báo về Machine Learning vào thời điểm năm 2023 mà không có cơ hội trải nghiệm thì coi như chưa đạt yêu cầu! 😊 Đọc xong bài post này, anh/chị có thể lấy ảnh chụp với người thân, bạn bè ra và đưa vào phần mềm phân vùng ảnh, tách các phân vùng mà anh/chị cho là hấp dẫn, lưu vào một thư mục nào đó. Tiếp đó, anh chị tải (upload) phân vùng ảnh đã lưu vào một phần mềm inpaint (vẽ nội ảnh) nào đó (DALL·E, Adobe Firefly, …) để tạo ra các bức ảnh, bức tranh nghệ thuật trong nháy mắt mà anh/chị không nhất thiết phải là một họa sỹ!
-
Ⓑ. Image Segmentation?
Nói qua một chút về phân vùng ảnh (Image Segmentation). Phân vùng ảnh là một phương pháp phân chia ảnh số thành các nhóm con, làm giảm độ phức tạp của ảnh và cho phép xử lý hoặc phân tích sâu hơn từng phân vùng.
Khi nhìn vào một ảnh, người ta có thể khoanh các vùng thuộc một lớp đối tượng nào đó (người, con vật, tòa nhà, …). Cách phân vùng ảnh theo lớp đối tượng có tên gọi là Semantic Segmentation (phân vùng theo lớp ngữ nghĩa).
Nếu trong cùng một lớp đối tượng, người ta lại phân biệt tiếp đối tượng A khác với đối tượng B, … thì cách phân vùng này có tên gọi là Instance Segmentation (phân vùng theo đối tượng). Như vậy, Instance Segmentation ngoài việc phân lớp còn dán nhãn cho từng đối tượng.
Chú ý rằng, khi nhìn vào ảnh, ngoài những “đối tượng” (là thứ có thể định hình được) còn nhiều chỗ “vô định hình” như bầu trời, mặt đất, biển, cát, … Cách phân vùng bao gồm cả thứ định hình được và vô định hình có tên gọi là Panoptic Segmentation (phân vùng toàn cảnh).
Ví dụ (nguồn):
Ảnh gốc:

-
Semantic Segmentation
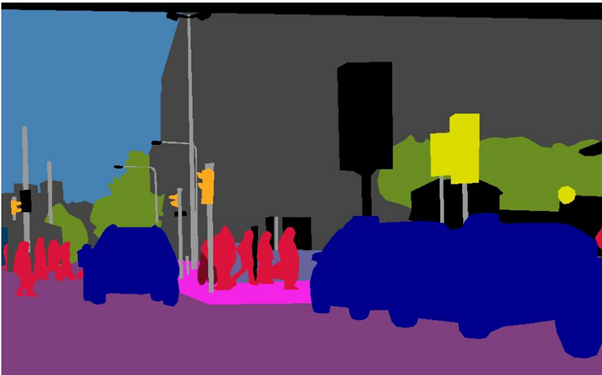
Người ta phân lớp đối tượng, chẳng hạn “người” là các phân vùng màu đỏ, ô tô là các phân vùng màu xanh, …
-
Instance Segmentation
Đối với Instance Segmentation, ngoài việc phân lớp đối tượng, người ta còn phân lập được các đối tượng khác nhau trong cùng một lớp.
-
Panoptic Segmentation

Panoptic Segmentation phân vùng ảnh bao gồm các thứ có thể định hình và thứ vô định hình.
-
Như vậy, khi ta lấy một điểm bất kỳ của ảnh (pixel) thì thuật toán phân vùng ảnh phải biết điểm đó thuộc lớp đối tượng nào, rồi trong lớp đó, điểm đó thuộc đối tượng A hay đối tượng B, … Chú ý rằng các lớp đối tượng, các đối tượng cụ thể có thể chồng lên nhau, giao nhau chứ không phải lúc nào cũng tách bạch rạch ròi.
-
Khi xem các ví dụ trên, dưới góc nhìn lập trình thì bài toán Image Segmentation có đầu vào là ảnh, đầu ra là tập hợp các khuôn đường viền – có tên gọi là mặt nạ (mask).
Một cách cô đọng:

Chốt lại: vấn đề của Image Segmentation là phải tạo ra tập hợp các mặt nạ. Và chất lượng của Image Segmentation nằm ở mức độ khớp của các mặt nạ (khoanh vùng) với các đối tượng trong ảnh.
-
Ⓒ. Computer Vision Foundation Model?
Những năm gần đây, đặc biệt là từ cuối năm 2022, đầu năm 2023, chúng ta đã chứng kiến sự bùng nổ của mô hình LLM (Large Language Model) mà đại diện tiêu biểu là ChatGPT. Cách tiếp cận của LLM là Pre-training (tiền huấn luyện) một kho ngữ liệu autoregressive (tự động tiếp diễn) khổng lồ không dán nhãn, dựa trên kiến trúc Transformer. Quá trình huấn luyện Pre-training cho phép LLM hiểu biết sâu về sắc thái của ngôn ngữ con người, bao gồm cú pháp, ngữ pháp, bối cảnh và thậm chí tham chiếu đến giá trị của các nền văn hóa khác nhau. Câu hỏi đặt ra đối với Computer Vision (thị giác máy tính) là liệu có một phương thức tương tự như cách tiếp cận của LLM hay không? Liệu có giải pháp nào xây dựng mô hình nền tảng (Foundation Model) như LLM hay không?
Người ta nhận thấy có một vài điểm khác biệt giữa mô hình ngôn ngữ (Language Model) và mô hình thị giác (Vision Model):
Kiến trúc khác nhau: Trong lúc mô hình ngôn ngữ xử lý một chuỗi các từ (word) được gán số thứ tự thì mô hình thị giác xử lý lưới các điểm (pixel) – các điểm này “bình đẳng” - không được sắp xếp theo một thứ tự nào cả. Trong một thời gian dài, cộng đồng Machine Learning xử lý mô hình thị giác chủ yếu dựa vào mạng CNN (Convolutional Neural Network). Mà CNN xử lý ảnh bằng cách áp dụng phép toán Convolution vào từng receptive field (vùng cảm nhận). CNN quét toàn bộ ảnh “bình đẳng như nhau”.
-
Mật độ thông tin khác nhau: Trong mô hình ngôn ngữ, mỗi một từ (word) bản thân nó đã giàu thông tin ngữ nghĩa. Khi ghép thành chuỗi, chúng tạo thành một khối thông tin “đậm đặc”. Trong khi đó, ảnh có rất nhiều thông tin dư thừa. Nhìn vào một ảnh, nếu chúng ta che một vài mảnh nhỏ thì với mắt thường thôi ai cũng có thể nhận dạng một cách dễ dàng ảnh gốc bằng cách “suy đoán” từ phần không che của ảnh. Nghĩa là cụm các điểm (pixel) trên ảnh chứa thông tin “rất loãng”.
-
Trên con đường đi tìm Vision Foundation Model (mô hình nền tảng cho thị giác), tháng 11/2021, một nhóm nghiên cứu ở FAIR (Facebook AI Research) – hiện nay thuộc MetaAI – đề xuất mô hình MAE (Masked Autoencoders). Ý tưởng của họ là sử dụng Autoencoder: mã hóa ảnh rồi giải mã dựng lại chính ảnh đấy, ảnh bất kỳ. Do tính chất này nên người ta huấn luyện mô hình mà không cần dán nhãn các ảnh. Phương thức tiếp cận của họ là sử dụng kiến trúc ViT: chia ảnh thành lưới các mảnh vụn, đánh số các mảnh này, rồi xếp chúng thành dãy các phần tử (token). Tuy nhiên, MAE có một điểm khác biệt so với ViT: trước khi mã hóa (trong kiến trúc Autoencoder), người ta che (masked) khoảng 75% số các mảnh vụn từ dãy các phần tử này. Phần giải mã là phục dựng lại ảnh (xem hình vẽ minh họa kiến trúc MAE). Chú ý sự khác biệt giữa cách tiếp cận của ViT và MAE so với CNN: các phần tử ảnh của ViT và MAE được đánh số thứ tự trong lúc các phần tử ảnh của CNN không có số thứ tự.
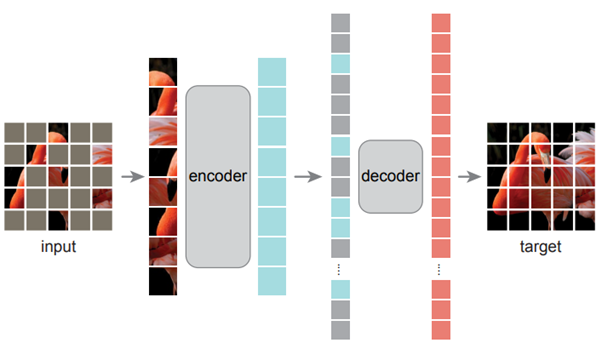
Kiến trúc MAE. (Nguồn)
-
Mô hình MAE đạt được những gì?
- Có thể huấn luyện với dữ liệu không dán nhãn. Do không cần dán nhãn nên người ta có thể thu thập dữ liệu ảnh với dung lượng lớn.
- Mô hình có thể mở rộng, nghĩa là có thể huấn luyện với khối lượng dữ liệu lớn hơn, từ đó số tham số (parameter) của mô hình tăng theo.
Thế MAE đã đạt đến LLM chưa? Chưa, và cảm giác là còn một khoảng cách khá xa để tiệm cận đến LLM. Lý do chính đã được nêu ở trên: phần tử nguyên tố trong mô hình ngôn ngữ (Language Model) là “từ” (word) có nghĩa (semantic) rất rõ ràng, còn phần tử nguyên tố trong mô hình thị giác (Vision Model) là điểm (pixel) thì chẳng có nghĩa gì (no semantic). Tuy nhiên, khi tập hợp các điểm lập thành một phân vùng (segment) nào đó thì phân vùng được thiết lập đó có thể có nghĩa (semantic). Nghĩa (semantic) của phân vùng nên được hiểu như thế nào? Bài báo kết luận là cần có các nghiên cứu sâu hơn theo hướng này.
-
Ⓓ. SAM (Segment Anything Model).
Như khẳng định trong phần đề dẫn của bài báo mục tiêu của dự án là xây dựng một mô hình nền tảng (Foundation Model) cho Image Segmentation (phân vùng ảnh). Trong lúc tham vọng của MAE là đi tìm mô hình nền tảng cho thị giác nói chung thì SAM thu hẹp lại là xây dựng mô hình nền tảng cho phân vùng ảnh. Chúng ta cùng xem họ đạt mục tiêu đến đâu.
SAM có đặc tính gần giống với LLM:
- Pre-training với một lượng dữ liệu đủ lớn để SAM trở thành mô hình tổng quát về Image Segmentation.
- Có thể truy vấn SAM giống như LLM: Prompt → SAM → Response.
-
Tất nhiên, Prompt, Response trong trường hợp của SAM khác với Prompt, Response trong trường hợp của LLM.
- Chúng ta biết rằng trong trường hợp LLM, Prompt là một cụm từ hoặc một cách tổng quát Prompt là một đoạn văn bản. Thế còn Prompt trong trường hợp mô hình SAM được hiểu như thế nào? Trong trường hợp SAM, Prompt có thể là một điểm, hình hộp, hình mặt nạ (mask) bao quanh một vật thể hoặc một cụm từ mô tả vật thể.
- Chúng ta đã biết hồi đáp Response trong trường hợp LLM là đoạn văn bản. Thế còn trong trường hợp mô hình SAM Response là gì? Response trong trường hợp của SAM không phải là đoạn văn bản mà là tập hợp các mặt nạ (mask).
-
Còn một điểm khác biệt nữa của SAM so với LLM. Trong trường hợp LLM, chúng ta chỉ cần đưa vào Prompt là đủ để truy vấn LLM. Trong trường hợp SAM, ngoài Prompt, chúng ta cần chỉ định cần truy vấn ảnh nào? Nghĩa là câu truy vấn bao gồm (Prompt và ảnh).
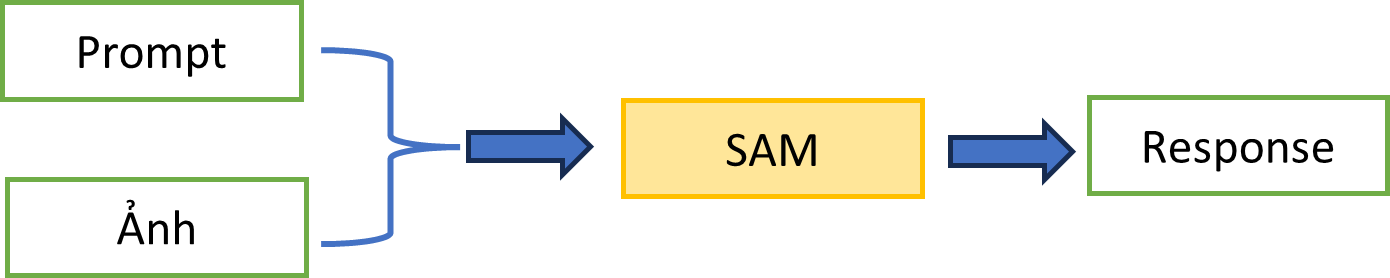
Để tối ưu hóa tốc độ xử lý, bước đầu tiên người ta tải ảnh lên, mã hóa ảnh. Sau đó, mỗi một lần áp Prompt thì chúng ta được Response tương ứng. Nghĩa là:
[Prompt] → [Ảnh mã hóa + SAM] → [Response]
-
Kiến trúc mô hình SAM
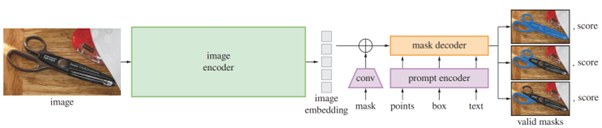
Kiến trúc mô hình SAM (nguồn).
Nhìn vào kiến trúc mô hình, một cách tổng quan, chúng ta thấy:
1. Đầu tiên, ảnh được mã hóa bằng image encoder:
[image] → [image encoder] → [Image Embedding]
Image encoder của họ là mô hình mạng MAE đã được tiền huấn luyện (Pre-training MAE). Nghĩa là ảnh đầu vào được chia thành lưới các mảnh vụn, sắp xếp thành chuỗi (image embedding), đánh số các mảnh vụn đó.
Ảnh được mã hóa một lần, và có thể được truy vấn (Prompting) nhiều lần.
-
2. Mỗi một lần truy vấn thì Prompt được mã hóa. Người ta chia Prompt thành 2 loại: loại rời rạc (sparse) gồm điểm, hình hộp, cụm từ và loại đặc (dense) là hình mặt nạ.
- Điểm: người ta mã hóa tọa độ (x, y) và xác định xem điểm đó thuộc một vật thể (foreground) hay thuộc nền ảnh (background).
- Hình hộp: người ta mã hóa tọa độ góc trái trên (x1, y1) và góc phải dưới (x2, y2).
- Cụm từ: người ta mã hóa đoạn văn bản bằng module Text Encoder từ CLIP.
- Hình mặt nạ: người ta mã hóa bằng phép toán Convolution, sau khi đã downsampling (thu nhỏ hình).
-
3. Bộ giải mã Mask Decoder: chúng ta có thể hình dung cách vận hành của bộ giải mã như sau:
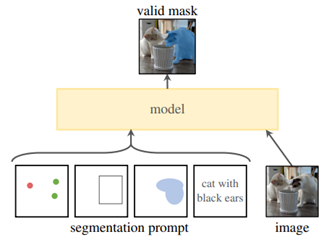
-
Dữ liệu huấn luyện SAM
SAM được xây dựng trên nền MAE tiền huấn luyện (Pre-training MAE). Tuy dữ liệu huấn luyện MAE không cần dán nhãn nhưng dữ liệu huấn luyện SAM lại cần dán nhãn.
- Nhãn để huấn luyện SAM là gì? Là mặt nạ bao vật thể: bản ghi dạng (ảnh → mặt nạ). Trong một ảnh thường có nhiều vật thể, đồng nghĩa với việc có nhiều mặt nạ tương ứng để bao các vật thể đó. Nếu ảnh có n vật thể thì người ta cần n nhãn dạng (ảnh → mặt nạ).
- Cần bao nhiêu nhãn? Vô cùng. Nghĩa là bao nhiêu nhãn cũng không đủ. Trong thực tế, các nhà công nghệ phải lấy cái hữu hạn để tiệm cận cái vô hạn. Tập hợp dữ liệu huấn luyện của SAM có 11 triệu ảnh, 1.1 tỷ mặt nạ (trung bình 1 ảnh có 100 mặt nạ). Tên của tập dữ liệu này được đặt tên là SA-1B (viết tắt của Segment Anything - 1 Billion). Tập dữ liệu này được xây dựng qua 3 giai đoạn là
1 - thủ công,
2 - bán tự động và
3 - tự động hoàn toàn.
-
Mô hình SAM đạt được những gì?
SAM đã đạt đến mô hình nền tảng (Foundation Model) cho phân vùng ảnh (Image Segmentation) hay chưa? Chưa hẳn.
- Tuy SAM dựa trên MAE huấn luyện dữ liệu không dán nhãn (tức là huấn luyện không giám sát) nhưng bản thân SAM huấn luyện với tập dữ liệu dán nhãn khổng lồ (huấn luyện có giám sát). Dù nhóm nghiên cứu sử dụng một công cụ dán nhãn tự động nhưng bản chất vấn đề vẫn không thay đổi: vẫn là cần dán nhãn.
- Liệu có tích hợp SAM vào một mô hình khác hoặc trở thành một module của một app nào đó? Vì SAM mới được công bố nên vấn đề này đang mở.
-
Gần đây nhất (so với thời điểm của bài post này) – ngày 30/08/2023, một nhóm nghiên cứu của trường ĐH Tứ Xuyên (Sichuan University) và Phòng thí nghiệm AI Thượng Hải (Shanghai AI Laboratory) công bố mô hình SAM-Med2D: áp dụng SAM để phân vùng ảnh y khoa (medical images). Họ nhận xét rằng mô hình gốc của SAM sử dụng trực tiếp cho ảnh y khoa kém hiệu quả, gặp nhiều lỗi: các mặt nạ tách ra từ ảnh “tự nhiên” không phù hợp với ảnh y khoa. Vì vậy, họ tiếp tục huấn luyện fine-tuning SAM với tập dữ liệu mới gồm 4.6 triệu ảnh y khoa và 19.7 triệu mặt nạ được “dán nhãn” từ tập ảnh đó. Ảnh được lấy từ các phương thức khác nhau: điện tử, laser, tia X, siêu âm, vật lý hạt nhân, cộng hưởng từ, … Có sự khác biệt đáng kể giữa hình ảnh tự nhiên và hình ảnh y khoa về mặt cường độ điểm ảnh, màu sắc, kết cấu và các đặc điểm phân bố khác. Họ mở mã nguồn trên GitHub tại GitHub - uni-medical/SAM-Med2D: SAM-Med2D: Bridging the Gap between Natural Image Segmentation and Medical Image Segmentation.
-
Đóng góp cơ bản của SAM:
- Có thể truy vấn SAM bằng Prompt, tuy chưa hoàn thiện. Trong phiên bản phần mềm thử nghiệm thì Prompt mới chỉ giới hạn trong điểm (point) và hình hộp bao (bounding box). Các tùy chọn khác như mặt nạ bao (mask) và cụm từ (text prompt) chưa thực hiện được.
- Có thể dùng SAM để phân vùng ảnh một cách tự động. Nghĩa là từ một ảnh, SAM có thể phân vùng toàn bộ ảnh: chỉ với một thao tác người ta tạo ra toàn bộ các mặt nạ bao quanh tất cả các vật thể.
- Tạo tập dữ liệu huấn luyện SA-1B cho cộng đồng. Tập dữ liệu 11 triệu ảnh, 1.1 tỷ mặt nạ giúp cho các nhóm nghiên cứu tiết kiệm được rất nhiều nguồn lực.
-
Ⓔ. Suy ngẫm chậm.
- Có thể cảm nhận rằng vào thời điểm hiện nay, xét về mức độ phát triển của các mô hình thì mô hình thị giác (Vision Model) bị bỏ lại phía sau so với mô hình ngôn ngữ (Language Model), mặc dù mô hình thị giác có công khởi động Machine Learning từ năm 2012, thu hút tài năng, nguồn lực cho cộng đồng này.
- 💡 Cách tiếp cận của SAM có một điểm đáng chú ý: đối với mô hình thị giác, đành chấp nhận huấn luyện có giám sát (dữ liệu cần dán nhãn). Để vượt qua bức tường Big Data họ lại tạo ra Data Engine: tập dữ liệu dán nhãn được sinh ra một cách tự động. Với Data Engine, người ta có thể mở rộng quy mô tập dữ liệu dán nhãn mà không cần tiêu tốn thêm nguồn lực. Có thể xem đây là một ý tưởng sáng tạo.
-
Cuối cùng, như thường lệ, tôi trân trọng mời anh/chị một cốc cà phê “ảo”. Cốc cà phê này được vẽ bởi phần mềm Bing Image Creator, Powered by DALL·E. Bằng mắt thường, chúng ta có thể dễ dàng nhận ra cốc cà phê được đặt trên một tách, bên cạnh là mấy miếng bánh bích quy. Tuy nhiên, nếu anh/chị đưa ảnh này vào thử với phần mềm SAM thì SAM gặp đôi chút khó khăn khi phân vùng ảnh vì bức tranh được vẽ theo trường phái ấn tượng, màu được quét theo liền một dải chứ không tách bạch rõ ràng như các tranh, ảnh khác.

-
Ⓕ. Phụ lục
①. Trải nghiệm mô hình SAM
Đường link: https://segment-anything.com/demo
Sau khi tải ảnh (Upload) hoặc chọn ảnh demo từ tập ảnh trưng bày (Gallery), phần mềm này có phần hướng dẫn trực tiếp ngay phía trái của màn hình: Tools (bộ công cụ).
Bộ công cụ gồm 3 nhóm:
- Hover & Click: Nhóm này tương đương với Point Prompt (điểm). Khi di chuột và click vào một điểm nào đó thì phần mềm sẽ gợi ý với mặt nạ bao điểm vừa click. Nếu để ở chế độ + (Add Mask) thì mặt nạ này sẽ được thêm vào vùng tổng (nếu có) đã chọn trước đó. Nếu để ở chế độ - (Remove Area) thì mặt nạ vừa chọn sẽ bị loại ra khỏi vùng tổng.
-
Sau khi đã chọn được “vật thể”, có thể cắt “vật thể” (dùng công cụ Cut out object) tách ra khỏi ảnh và sao chép vào hộp Cut-Outs. Phần mềm dùng từ Cut out object thật ra là không chính xác. Thực chất của thao tác này sao chép vật thể đã xác định vào hộp Cut-Outs. Vật thể gốc không bị cắt ra khỏi ảnh.
- Box: Nhóm này tương đương với Box Prompt (bao hình hộp). Tỳ chuột trái, đồng thời di chuột để tạo một hình chữ nhật bao vật thể mục tiêu. Khi đã phủ vật thể rồi thì nhả chuột. Phần còn lại giống với các thao tác ở Hover &Click.
- Everything: Nhóm này không có Prompt tương đương. Khi chọn công cụ này thì phần mềm sẽ tìm tất cả các vật thể có trong ảnh và phân vùng chúng bằng các mặt nạ. Có thể dùng phép toán Cut out all objects để chép toàn bộ các vật thể đó vào hộp Cut-Outs.
-
Ngoài ba nhóm công cụ trên, chúng ta còn thấy hộp Cut-Outs: hộp này chứa tất cả các vật thể được cắt ra từ các nhóm công cụ trên. Các “vật thể” này thực chất là các ảnh. Vì là ảnh nên chúng có thể được sao chép (Copy image), tải xuống (Save image as …), …
-
②. Thước đo IoU (Intersection over Union)
Trong mô hình Image Segmentation, cũng giống như các mô hình khác, chúng ta biết rằng cách thức Machine Learning xử lý vấn đề là huấn luyện mô hình mạng nơ-ron (Neural Network) với một tập hợp dữ liệu đủ lớn các bản ghi được dán nhãn dạng:
[Ảnh → mặt nạ]
[Ảnh → mặt nạ]
…
[Ảnh → mặt nạ]
-
Tại mỗi một bước huấn luyện, máy so sánh mặt nạ thật với mặt nạ phỏng đoán (predicted) của mô hình. Từ so sánh (mặt nạ thật, mặt nạ phỏng đoán) máy sẽ điều chỉnh trọng số của mô hình. Để biết được độ khớp của “mặt nạ phỏng đoán” so với “mặt nạ thật”, người ta sử dụng thước đo có tên là Intersection over Union, viết tắt là IoU. Đây là phép chia của phần diện tích giao nhau trên tổng diện tích của 2 mặt nạ (thật và phỏng đoán) – Xem ảnh minh họa. Nếu mặt nạ phỏng đoán khớp hoàn toàn với mặt nạ thật thì tỷ số này bằng 1. Tệ nhất là khi 2 mặt nạ không có phần nào giao nhau – trường hợp này tỷ số bằng 0.
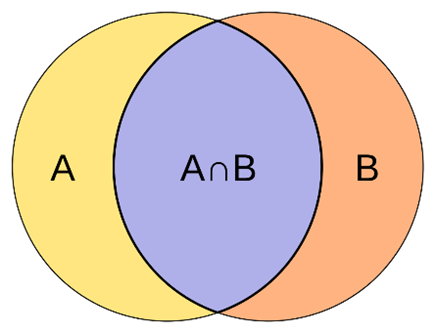
Nguồn.
Ảnh minh họa thước đo IoU.
-
Ví dụ:
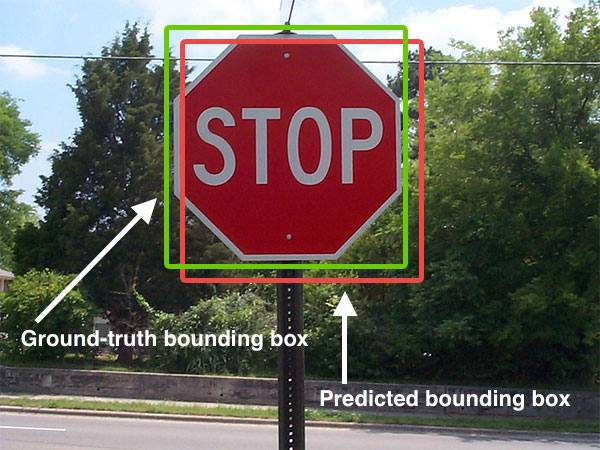
Nguồn.
Trong ví dụ trên, khung màu xanh là mặt nạ thật, còn khung màu đỏ là mặt nạ phỏng đoán. Và cách tính IoU như sau:

Nguồn.
-
Minh họa chất lượng IoU:
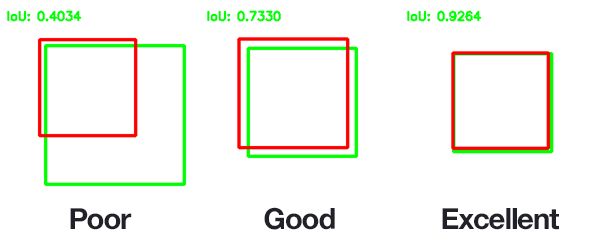
Nguồn.
Giá trị IoU nằm trong khoảng [0, 1]. IoU = 0 khi 2 mặt nạ (thật và phỏng đoán) không có phần giao nhau. IoU = 1 khi 2 mặt nạ khớp nhau hoàn toàn.
-
