Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Machine Learning.
- Tính thời sự: Tháng 11/2022.
- Thời gian đọc: 6 phút.
~
Báo cáo với anh/chị, bài post này tôi đóng vai “thầy bói xem voi”: rà soát và đọc các bài báo có liên quan đến ChatGPT mà OpenAI đăng tải từ hồi năm 2015 cho đến nay (thông qua các bài blog trên trang web của họ) rồi “đoán mò” xem họ “dựng” ChatGPT như thế nào. Mà đã là đoán mò thì chẳng có gì đảm bảo là đúng 100%! Tôi phải “cảnh báo” trước như thế - anh/chị đọc bài post này cốt là để nhâm nhi cà phê thôi nha, đừng coi nó có chút “hàn lâm” nào cả 😊.
-
Đề dẫn.
Chúng ta biết rằng bản chất các mô hình LLM (Large Language Model) như GPT-2, GPT-3 là đoán từ tiếp theo của một dãy các từ cho trước. Hãy lấy một ví dụ cho dễ hiểu.
Nếu chúng ta yêu cầu mô hình điền từ tiếp theo của dãy từ Ngẫm hay muôn sự tại ❓ thì mô hình sẽ xác định bằng cách xem trong toàn bộ từ điển (khoảng mấy trăm nghìn từ) từ nào có xác suất cao nhất sẽ xuất hiện. Chẳng hạn, từ ngữ cảnh của câu trên, máy lọc ra các từ “trời”, “đất”, “người”, … Nhận thấy từ “trời” có xác suất cao nhất nên nó chọn từ này và được kết quả là Ngẫm hay muôn sự tại trời. Tương tự, nếu chúng ta yêu cầu máy điền một dãy từ tiếp theo câu trên thì máy thực hiện cùng một thuật toán và được kết quả, lấy ví dụ, chuỗi văn bản sau:
Ngẫm hay muôn sự tại trời,
Trời kia đã bắt làm người có thân.
Bắt phong trần phải phong trần,
Cho thanh cao mới được phần thanh cao.
-
Như vậy, hàm mục tiêu (objective function) ban đầu của LLM là tìm từ hoặc đoạn văn bản tiếp theo sao cho xác suất xuất hiện là cao nhất.

-
Bản chất vấn đề nằm ở chỗ LLM “không hiểu” ngữ nghĩa của Prompt và càng không hiểu dụng ý của người dùng (user’s intention), là nội hàm của Prompt. Làm thế nào để LLM “hiểu” được Prompt và phát sinh Response một cách tương ứng?
-
Vào quãng thời gian năm 2018, cộng đồng nghiên cứu Machine Learning bắt đầu tranh luận và tìm các giải pháp nhằm làm cho đầu ra Response trả lời đúng ý của truy vấn đầu vào Prompt. Trong tiếng Anh người ta gọi vấn đề này là Alignment. Tôi tạm dịch từ này theo một số tùy chọn: cân chỉnh | nắn | khớp. Báo cáo với anh/chị, trong bài post này tôi dùng tùy chọn “khớp” trong ngữ cảnh ở trên: LLM cần phát sinh đầu ra Response “khớp” với dụng ý của truy vấn Prompt.
-
Còn một vấn đề nữa: khớp theo “mấu khớp” nào? Tức là phải có bộ tiêu chí để khớp chứ!? Trong lần nhàn đàm trước trên diễn đàn này tôi đã đề cập các tiêu chí khớp của OpenAI: họ dựa vào một đề xuất, đề xuất này cho rằng việc khớp Response với Prompt cần thỏa mãn 3 tiêu chí, đó là hữu ích (helpful), trung thực (honest) và vô hại (harmless).
-
Reward Model.
Làm thế nào để biết được Response do LLM tạo ra có khớp với Prompt hay không? Và nếu khớp thì đánh giá mức độ khớp theo cách nào? Lưu ý rằng máy không hề hiểu nội dung của Prompt.
Người ta chọn cách sử dụng nguồn lực con người nhằm đọc hiểu truy vấn Prompt rồi đánh giá mức độ khớp của Response.
Để thực hiện việc này người ta gán với mỗi một cặp (Prompt, Response) một điểm số, có tên gọi là Reward. Reward càng cao thì Response càng khớp với Prompt.

-
Cách đặt vấn đề này đưa chúng ta trở lại với vấn đề Reinforcement Learning (RL). Để giúp anh/chị đỡ mất thời gian lục tìm trên mạng, tôi xin phép “diễn nôm” RL: RL là một lĩnh vực con của Machine Learning, nghiên cứu cách thức một Agent trong một môi trường nên chọn thực hiện các hành động (Action) nhằm cực đại hóa một khoản thưởng (Reward) nào đó về lâu dài.
Trong trường hợp LLM phát sinh Response từ Prompt ([Prompt] → [LLM] → [Response]) thì LLM chính là Agent. Việc của Agent (LLM) là từ một Prompt cần tìm Response sao cho Reward đạt giá trị cực đại. Theo ngôn ngữ RL thì LLM cần tìm ra một Policy (chiến lược) tối ưu cho việc phát sinh Response từ một Prompt.
Nhưng trước hết làm sao biết được giá trị của Reward khi cho cặp (Prompt, Response)? Hay nói một cách khác làm thế nào để tìm hàm Reward (Prompt, Response)?
Ý tưởng ▼
Lục tìm trong các kết quả nghiên cứu trước đây, OpenAI lấy ý tưởng từ bài báo đăng từ hồi năm 2017: “Deep reinforcement learning from human preferences” (DRLHP). DRLHP thuộc lớp inverse reinforcement learning (IRL). Nghĩa là cho biết kết quả, máy phải tìm hàm ngược.
Khi nghiên cứu RL về trò chơi Atari và mô phỏng quỹ đạo của các robot, người ta thường rất khó để tìm được hàm Reward (hàm xuôi). Lý do là hàm này thường gồm nhiều tham số phức tạp, rất khó xác định được bản chất – không khả thi để “viết” ra được hàm toán học hoặc hàm lập trình. Các tác giả bài báo đề xuất cách tiếp cận là cho phép người giám sát hệ thống cung cấp phản hồi và sử dụng phản hồi này để tiệm cận giá trị của hàm Reward bằng Deep Learning.
Phản hồi của người giám sát được thực hiện như thế nào? Rất đơn giản: người giám sát hệ thống quan sát cặp quỹ đạo (trajectory) bắt đầu cùng một trạng thái nhưng kết thúc ở hai trạng thái khác nhau rồi chọn quỹ đạo ưu thích. Giả thiết ký hiệu 2 quỹ đạo có cùng điểm xuất phát là q1 và q2, việc của người giám sát là chọn q1 hay q2. Nếu người giám sát thích quỹ đạo q1 hơn quỹ đạo q2 thì q1 nhận được một khoản thưởng và q2 nhận một khoản phạt và ngược lại.
Sau đó, người ta thiết lập một mạng nơ-ron (Neural Network). Đầu vào của mạng nơ-ron này là các cặp phản hồi của người giám sát – ký hiệu là q1 ÷ q2. Đầu ra là giá trị vô hướng r (Reward). Sau khi huấn luyện với một lượng đủ lớn các cặp phản hồi (q1 ÷ q2), thì mạng nơ-ron này được xem là hàm Reward cần tìm (cho kết quả gần đúng). Nghĩa là, cho đầu vào cặp (Prompt, Response) mạng sẽ “suy diễn” ra một giá trị Reward.
Ý tưởng ▲
-
Giải pháp tổng thể.
Cách tiếp cận của OpenAI được thực hiện theo các bước sau:
Bước 1: Fine-tuning.
Đầu vào là LLM ở bước Pre-training. (OpenAI không nói rõ phiên bản Pre-training, chỉ khẳng định lấy LLM từ GPT-3.5 series.)
Người dùng truy vấn LLM:
[Prompt] → [LLM] → [Response]
Như vậy, quy trình Fine-tuning là tạo ra tập mẫu:
[Prompt1, Response1]
[Prompt2, Response2]
…
[Promptn, Responsen]
-
Tập mẫu [Prompt, Response] lấy từ đâu? OpenAI thuê đội ngũ dán nhãn thực hiện. Người dán nhãn vừa thiết kế Prompt vừa viết trực tiếp đầu ra Response.
Sau bước tinh chỉnh này, người ta được một mô hình có tên gọi là SFT model (Supervised fine-tuning). Mô hình này đóng vai là baseline model - mô hình cơ sở.

-
Bước 2: Reward Model.
Cách tạo tập mẫu để huấn luyện:
* xuất phát từ 1 Prompt, mô hình tạo ra k Response (k: từ 4 đến 9).
* Đối với từng cặp Response1 và Response2 phát sinh từ cùng một Prompt, người dán nhãn (labeler) có nhiệm vụ chỉ định họ “thích” Response nào hơn (Response1 hay Response2).
* Tổ hợp lại, người ta sắp xếp các Response theo thứ tự từ “thích” nhất đến “chê” nhất.
Chúng ta hình dung bước này thông qua ví dụ sau:
Từ một đầu vào (Prompt) có các đầu ra (Response) tương ứng là 🅐, 🅑, 🅒 và 🅓. Sau khi người dán nhãn chỉ định việc so sánh từng cặp, tổ hợp lại thì được kết quả như sau (dấu “≻” chỉ định việc người dán nhãn “thích”):
🅓 ≻ 🅒 ≻ 🅐 ≻ 🅑
Tức là Response 🅓 được “thích” nhất và Response 🅑 bị “chê” nhất.
⚠ Chú ý: Dưới góc nhìn của RL thì Response là quỹ đạo (trajectory), LLM là Agent, người dán nhãn (labeler) là người giám sát hệ thống (xem phần ý tưởng ở trên).
Tập mẫu dữ liệu “thích” này được dùng để huấn luyện Reward Model.

Sau khi được huấn luyện, Reward Model trở thành hàm Reward trong RL, nghĩa là nếu cho cặp (Prompt, Response) làm đầu vào thì mô hình Reward Model sẽ tính ra được một giá trị vô hướng Reward (xem phần ý tưởng ở trên):
Reward Model (Prompt, Response) → Giá trị vô hướng Reward
-
Bước 3: Optimize Policy.
a) Lấy 1 Prompt từ tập dữ liệu mẫu
b) Mô hình PPO được khởi tạo từ Policy của SFT Model
c) PPO vận hành tạo ra Response
d) rk ← Reward Model (Prompt, Response) (dùng Reward Model để tính rk)
e) Reward rk được dùng để cập nhật mô hình PPO và quay lại bước b)
-
Vòng lặp b) – e) được lặp đi lặp lại cho đến khi rk hội tụ (nghĩa là rk của bước trước và rk+1 của bước tiếp theo không có sự khác biệt đáng kể).
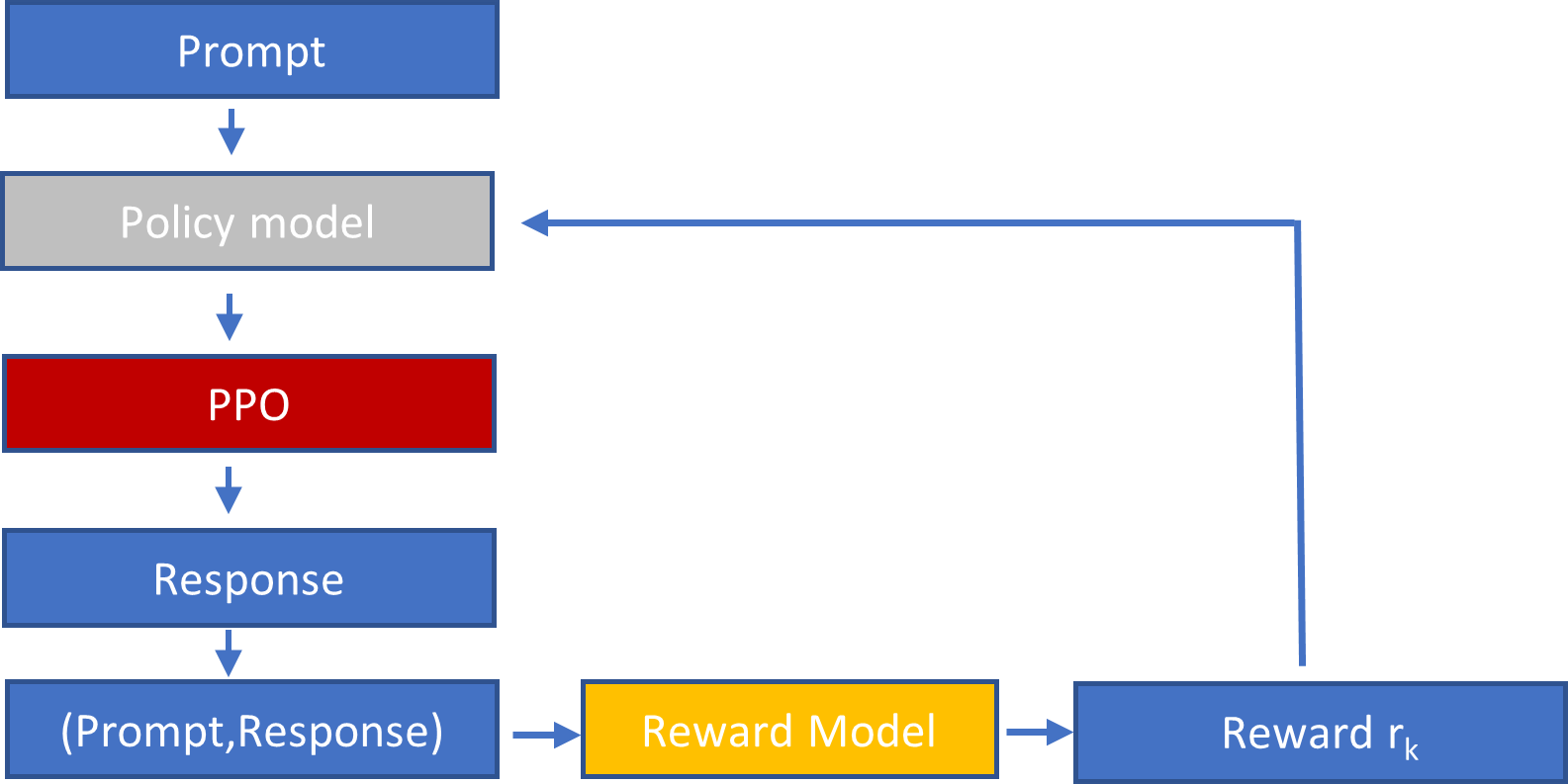
Giải thích ▼
PPO là viết tắt của Proximal Policy Optimization Algorithms.
Ý tưởng cốt lõi của PPO là tối ưu hóa Policy một cách “từ tốn”, tránh các bước “nhảy ra khỏi vùng an toàn”. Nếu chúng ta tưởng tượng Policy là một quỹ đạo thì PPO tối ưu hóa quỹ đạo tiếp theo từ quỹ đạo cũ (ngay trước đó) bằng một biến đổi đủ nhỏ và an toàn nhằm giữ cho hệ thống luôn luôn ổn định (stable).
Giải thích ▲
-
Bước 1 chỉ diễn ra một lần.
Bước 2 và bước 3 được lặp lại liên tục. Chú ý đến tính tương tác của Reward Model và Policy Model.
- Sau khi người dùng đưa vào một Prompt thì PPO tối ưu hóa Policy (tức là tạo ra Response tối ưu từ Prompt). Từ đó, Policy Model hoàn thiện hơn.
- Trong quá trình tối ưu hóa Response, PPO tạo ra một chuỗi các cặp (Prompt, Response1), (Prompt, Response2), … (Prompt, Responsen). Nghĩa là cùng một đầu vào Prompt, PPO đã tạo ra n Response khác nhau. Nếu bây giờ họ dùng việc so sánh các cặp (Responsei ≻ Responsek) để huấn luyện tiếp Reward Model (xem bước 2 ở trên) thì Reward Model được tiếp tục hoàn thiện.
Nghĩa là: càng có nhiều hội thoại thì hệ thống càng hoàn thiện.
-
Sau 2 tháng ra mắt, ChatGPT có hơn 100 triệu người dùng, hàng ngày có khoảng 13 triệu người ghé thăm thì chúng ta hiểu hệ thống được hoàn thiện đến mức nào!
---
Trước khi kết thúc bài post, tôi nhờ chú thỏ “ảo” mời anh/chị một tách cà phê. Bức họa chú thỏ, tôi cũng nhờ phần mềm DALL·E của OpenAI vẽ. Bây giờ OpenAI được đề cập khắp mọi nơi nên tôi cũng đành phải đi theo trend đó. 😊

