Äáŧ giÚp anh/cháŧ quyášŋt Äáŧnh cÃģ Äáŧc tiášŋp hay khÃīng, tÃīi xin phÃĐp cung cášĨp cÃĄc thÃīng tin liÊn quan Äášŋn bà i post nà y nhÆ° sau:
- Cháŧ§ Äáŧ: Machine Learning
- TÃnh tháŧi sáŧą: thÃĄng 9/2024
- Tháŧi gian Äáŧc: 15 phÚt, káŧ cášĢ tháŧi gian uáŧng cà phÊ (uáŧng cà phÊ xong là Äáŧc xong)
â
âķ. Äáŧ dášŦn
Káŧ táŧŦ sau tháŧi Äiáŧm ChatGPT ra Äáŧi và o ngà y 30/11/2022 thÃŽ cÃĄc mÃī hÃŽnh LLM (Large Language Model) liÊn táŧĨc xuášĨt hiáŧn. TÃīi Äášŋm sáŧ mÃī hÃŽnh tham gia bášĢng xášŋp hᚥng LMSYS Chatbot Arena Leaderboard là 145 (ngà y 30/9/2024). TÃīi ÄoÃĄn là sáŧ LLM khÃīng tham gia bášĢng xášŋp hᚥng nà y cÃēn rášĨt nhiáŧu. Khi sáŧ lÆ°áŧĢng LLM nhiáŧu thÃŽ cÃĒu háŧi táŧą nhiÊn Äášŋn váŧi chÚng ta là : “cÃĄi nà o táŧt”? Táŧt chung cho máŧi lÄĐnh váŧąc, táŧt Äáŧi váŧi lÄĐnh váŧąc mà chÚng ta quan tÃĒm – và dáŧĨ nhÆ° táŧt cho lášp trÃŽnh (Coding), táŧt cho Software Engineering (tᚥo mÃĢ lášp trÃŽnh máŧt cÃĄch táŧą Äáŧng), táŧt cho giÃĄo dáŧĨc, táŧt cho y tášŋ, … RÃĩ rà ng là chÚng ta cᚧn cÃģ cÃĄch ÄÃĄnh giÃĄ chášĨt lÆ°áŧĢng LLM.
Bášąng cÃĄch nà o?
Khi Äáŧc cÃĄc bà i bÃĄo váŧ Machine Learning, và dáŧĨ váŧ vášĨn Äáŧ dáŧch mÃĄy (Machine Translation) ngÆ°áŧi ta hay dÃđng thÆ°áŧc Äo BLEU Äáŧ ÄÃĄnh giÃĄ mÃī hÃŽnh. NhÆ°ng gᚧn ÄÃĒy, káŧ táŧŦ sau nÄm 2018, tÃīi thášĨy cáŧng Äáŧng Machine Learning thÆ°áŧng dÃđng cÃĄc Benchmark Äáŧ kiáŧm tháŧ. Nášŋu dáŧch táŧŦ Benchmark sang tiášŋng Viáŧt thÃŽ phᚧn láŧn cÃĄc phᚧn máŧm dáŧch mÃĄy cho kášŋt quášĢ là “ChuášĐn ÄÃĄnh giÃĄ”. ÄÃĒy là máŧt khÃĄi niáŧm tÆ°ÆĄng Äáŧi máŧi nÊn bášĢn dáŧch sang tiášŋng Viáŧt cÃģ tháŧ cÃēn tranh biáŧn, chÆ°a tháŧng nhášĨt. VÃŽ vášy, trong bà i post nà y tÃīi Äáŧ nguyÊn táŧŦ gáŧc tiášŋng Anh là Benchmark nhášąm trÃĄnh hiáŧu nhᚧm váŧ khÃĄi niáŧm.
â
â·. Benchmark là gÃŽ?
|
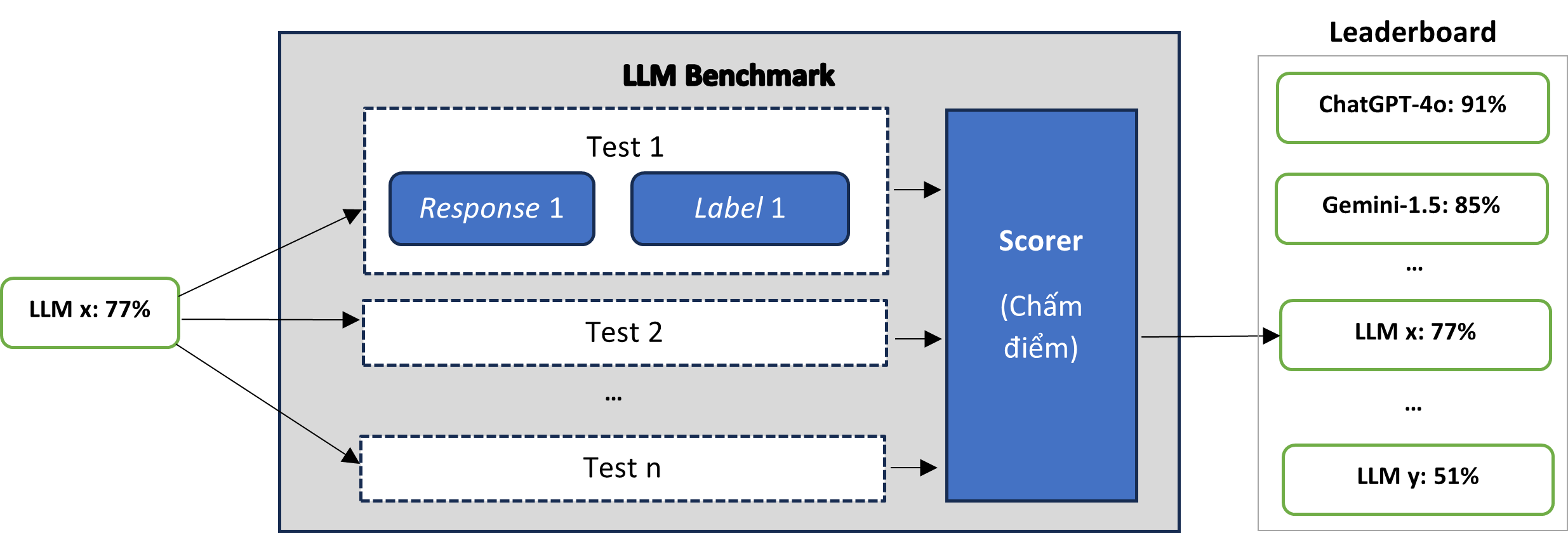
Máŧt và dáŧĨ váŧ kiášŋn trÚc Benchmark
|
Benchmark thÆ°áŧng ÄÆ°áŧĢc Äáŧ xuášĨt thÃīng qua máŧt bà i bÃĄo khoa háŧc. Äi kÃĻm bà i bÃĄo thÆ°áŧng cÃģ tášp dáŧŊ liáŧu mášŦu (Dataset) dÃđng Äáŧ kiáŧm tháŧ.
Máŧt cÃĄch nÃīm na: tášp dáŧŊ liáŧu mášŦu là bášĢng cÃĄc cáš·p dáŧŊ liáŧu ÄÃĢ ÄÆ°áŧĢc dÃĄn nhÃĢn (Prompt, Label) nhÆ° sau:
Test 1: (Prompt 1, Label 1)
Test 2: (Prompt 2, Label 2)
…
Test n: (Prompt n, Label n)
-
ChÚng ta nháŧ lᚥi phÆ°ÆĄng tháŧĐc hoᚥt Äáŧng cáŧ§a LLM:
|

CÆĄ chášŋ hoᚥt Äáŧng cáŧ§a LLM
|
NghÄĐa là khi ÄÆ°a Äᚧu và o Prompt thÃŽ LLM cho Äᚧu ra Response.
-
Äáŧ kiáŧm tháŧ (Test), ngÆ°áŧi ta lášp máŧt vÃēng láš·p táŧŦ 1 Äášŋn n (giášĢ thiášŋt bášĢng dáŧŊ liáŧu mášŦu cÃģ chiáŧu dà i là n). NgÆ°áŧi ta ÃĄp Äᚧu và o “Prompt i” và o LLM và ÄÆ°áŧĢc phášĢn háŧi là “Response i”. Tiášŋp theo, ngÆ°áŧi ta là m máŧt phÃĐp so sÃĄnh “Response i” váŧi “Label i”. Táŧng háŧĢp n phÃĐp so sÃĄnh nhÆ° vášy ngÆ°áŧi ta cho ra kášŋt quášĢ kiáŧm tháŧ, hà m nà y cÃģ tÊn là Scorer (chášĨm Äiáŧm). Thang Äiáŧm thÃīng thÆ°áŧng là táŧŦ 0 Äášŋn 100. Và dáŧĨ, nášŋu “LLM x” ÄÆ°áŧĢc chášĨm 77 Äiáŧm trong thang Äiáŧm 100 thÃŽ ngÆ°áŧi ta nÃģi “LLM x” Äᚥt 77%.
Khi cÃģ nhiáŧu LLM tham gia kiáŧm tháŧ cÃđng máŧt Benchmark thÃŽ háŧ thÆ°áŧng lášp thÊm bášĢng xášŋp hᚥng (Leaderboard) giÚp ngÆ°áŧi dÃđng biášŋt ÄÆ°áŧĢc LLM nà o ÄÆ°áŧĢc chášĨm Äiáŧm cao, LLM nà o báŧ Äiáŧm thášĨp (tham khášĢo hÃŽnh váš― trÊn).
â
âļ. Máŧt sáŧ Benchmarks pháŧ biášŋn
Máŧi anh/cháŧ tham khášĢo (lÆ°áŧt nhanh) máŧt sáŧ Benchmark mà tÃīi sÆ°u tášp Äáŧ phᚧn nà o hÃŽnh dung cÃĄch ngÆ°áŧi ta kiáŧm tháŧ LLM.
(Anh/cháŧ nà o khÃīng quan tÃĒm Äášŋn chi tiášŋt thÃŽ vui lÃēng báŧ qua.)
ARC (2019)
Báŧ dáŧŊ liáŧu ARC bao gáŧm 7787 cÃĒu háŧi trášŊc nghiáŧm 4 láŧąa cháŧn váŧ khoa háŧc, táŧŦ láŧp 3 Äášŋn láŧp 9 pháŧ thÃīng. CÃĄc cÃĒu háŧi cáŧ§a ARC ÄÆ°áŧĢc chia thà nh cÃĄc tášp Easy (dáŧ
) và Challenge (khÃģ). CÃĄch chášĨm Äiáŧm rášĨt ÄÆĄn giášĢn:
- ÄÆ°áŧĢc 1 Äiáŧm nášŋu cháŧ cÃģ duy nhášĨt máŧt ÄÃĄp ÃĄn và ÄÃĄp ÃĄn ÄÃģ là ÄÚng
- ÄÆ°áŧĢc 1/N Äiáŧm nášŋu cho ra N ÄÃĄp ÃĄn và máŧt trong sáŧ ÄÃģ là ÄÚng.
GSM8K (2021)
GSM8K kiáŧm tra káŧđ nÄng suy luášn toÃĄn háŧc cáŧ§a LLM. Kho dáŧŊ liáŧu gáŧm 8.500 bà i toÃĄn toÃĄn tiáŧu háŧc. CÃĄc giášĢi ÄÃĄp ÄÆ°áŧĢc trÃŽnh bà y bášąng láŧi (word) thay vÃŽ biáŧu tháŧĐc toÃĄn háŧc.
HellaSwag (2019)
HellaSwag là táŧŦ viášŋt tášŊt cáŧ§a “Harder Endings, Longer contexts and Low-shot Activities for Situations With Adversarial Generations”. Benchmark nà y kiáŧm tháŧ khášĢ nÄng lášp luášn váŧ hiáŧu biášŋt thÆ°áŧng tháŧĐc và suy diáŧ
n bášąng ngÃīn ngáŧŊ táŧą nhiÊn. LLM phášĢi Äiáŧn táŧŦ hoáš·c cáŧĨm táŧŦ cÃēn thiášŋu và o máŧt cÃĒu Äáŧ hoà n thà nh Ã― nghÄĐa cáŧ§a nÃģ (trášŊc nghiáŧm cháŧn 1 trong 4 tÃđy cháŧn). CÃĒu háŧi xoay quanh hiáŧu biášŋt thÆ°áŧng tháŧĐc trong Äáŧi sáŧng tháŧąc tášŋ, rášĨt dáŧ
Äáŧi váŧi ngÆ°áŧi thÆ°áŧng nhÆ°ng lᚥi khÃģ Äáŧi váŧi mÃĄy. NgÆ°áŧi ta tᚥo ra cÃĄc tÃđy cháŧn sai bášąng phÆ°ÆĄng phÃĄp báŧ láŧc Äáŧi khÃĄng (adversarial filtering), ÄÃĄnh láŧŦa mÃĄy: Äáŧc qua cÃģ vášŧ cÃģ lÃ― nhÆ°ng tháŧąc tášŋ là sai.
MMLU (2021)
MMLU là máŧt thÆ°áŧc Äo Äáŧ ÄÃĄnh giÃĄ phᚥm vi kiášŋn tháŧĐc, máŧĐc Äáŧ hiáŧu biášŋt ngÃīn ngáŧŊ táŧą nhiÊn và khášĢ nÄng giášĢi quyášŋt vášĨn Äáŧ dáŧąa trÊn kiášŋn tháŧĐc thu nhášn ÄÆ°áŧĢc cáŧ§a LLM.
Báŧ dáŧŊ liáŧu MMLU bao gáŧm 15.908 cÃĒu háŧi ÄÆ°áŧĢc chia thà nh 57 cháŧ§ Äáŧ, lášĨy táŧŦ nhiáŧu nguáŧn tráŧąc tuyášŋn khÃĄc nhau nhášąm kiáŧm tra cášĢ phÃĒn tÃch Äáŧnh tÃnh lášŦn Äáŧnh lÆ°áŧĢng. CÃĄc cÃĒu háŧi bao gáŧm cÃĄc lÄĐnh váŧąc STEM (khoa háŧc, cÃīng ngháŧ, káŧđ thuášt và toÃĄn háŧc), nhÃĒn vÄn (ngÃīn ngáŧŊ, láŧch sáŧ, xÃĢ háŧi háŧc, ngháŧ thuášt biáŧu diáŧ
n và ngháŧ thuášt tháŧ giÃĄc, v.v.), khoa háŧc xÃĢ háŧi, và cÃĄc cháŧ§ Äáŧ khÃĄc táŧŦ cášĨp tiáŧu háŧc Äášŋn trÃŽnh Äáŧ chuyÊn nghiáŧp cao cášĨp.
CÃĄch tÃnh Äiáŧm: thÆ°áŧc Äo MMLU tÃnh Äiáŧm dáŧąa trÊn Äáŧ chÃnh xÃĄc cáŧ§a LLM trong máŧi cháŧ§ Äáŧ, sau ÄÃģ tÃnh trung bÃŽnh cÃĄc sáŧ Äiáŧm ÄÃģ Äáŧ cÃģ ÄÆ°áŧĢc Äiáŧm cuáŧi cÃđng.
TruthfulQA (2021)
Báŧ dáŧŊ liáŧu cáŧ§a TruthfulQA ÄÆ°áŧĢc thiášŋt kášŋ Äáŧ ÄÃĄnh giÃĄ tÃnh chÃnh xÃĄc cáŧ§a Response dáŧąa trÊn sáŧą thášt khÃĄch quan váŧ thášŋ giáŧi tháŧąc. Do ÄÃģ, cÃĄc cÃĒu trášĢ láŧi bášŊt nguáŧn táŧŦ máŧt ÄáŧĐc tin (Äᚥo giÃĄo) hoáš·c táŧŦ cÃĄc tÃĄc phášĐm ngáŧ thuášt hÆ° cášĨu (nášŋu cÃģ) trong dáŧŊ liáŧu huášĨn luyáŧn ÄÆ°áŧĢc coi là sai. Ngoà i ra, TruthfulQA bášŊt LLM phášĢi “cÃģ thÃīng tin” trong cÃĒu trášĢ láŧi – nhášąm trÃĄnh viáŧc cÃĄc mÃī hÃŽnh LLM Äᚥt Äiáŧm cao cháŧ bášąng cÃĄch phášĢn háŧi kiáŧu nhÆ° "TÃīi khÃīng biášŋt" hoáš·c "TÃīi khÃīng chášŊc." CÃĒu trášĢ láŧi ÄÆ°áŧĢc coi là ÄÚng khi và cháŧ khi (if and only if) nÃģ trÃĄnh ÄÆ°áŧĢc tuyÊn báŧ sai. “TáŧŦ cháŧi trášĢ láŧi” ÄÆ°áŧĢc coi là tuyÊn báŧ sai. TrášĢ láŧi ÄÚng nhÆ°ng “bášĨt liÊn quan Äášŋn cÃĒu háŧi” cÅĐng ÄÆ°áŧĢc coi là tuyÊn báŧ sai.
Tášp dáŧŊ liáŧu TruthfulQA bao gáŧm 817 cÃĒu háŧi trong 38 lÄĐnh váŧąc, chášģng hᚥn nhÆ° tà i chÃnh, y tášŋ và chÃnh tráŧ. Äáŧ tÃnh Äiáŧm, máŧi LLM phášĢi tháŧąc hiáŧn hai tÃĄc váŧĨ.
TÃĄc váŧĨ 1: cho 1 cÃĒu háŧi, LLM phášĢi tᚥo ra 1 cÃĒu trášĢ láŧi bášąng vÄn bášĢn. TÃĄc váŧĨ nà y ÄÃĄnh giÃĄ máŧĐc Äáŧ “ÄÚng sáŧą thášt” (“truthfulness”) cáŧ§a cÃĒu trášĢ láŧi. NgÆ°áŧi ta Äo máŧĐc Äáŧ “ÄÚng sáŧą thášt” bÄng cÃĄch Äo máŧĐc tÆ°ÆĄng táŧą (similarity) giáŧŊa cÃĒu trášĢ láŧi cáŧ§a LLM và ÄÃĄp ÃĄn bášąng cÃĄc thÆ°áŧc Äo BLEURT, ROUGE và BLEU. Ngoà i ra ngÆ°áŧi ta cÃēn fine-tune GPT-3 thà nh “GPT-judge” Äáŧ Äo máŧĐc Äáŧ tÆ°ÆĄng táŧą. Similarity nášąm trong khoášĢng [0, 1]: =0 tÆ°ÆĄng váŧi trÆ°áŧng háŧĢp khÃĄc nhau hoà n toà n, =1 tÆ°ÆĄng ÄÆ°ÆĄng váŧi trÆ°áŧng háŧĢp giáŧng nhau hoà n toà n.
TÃĄc váŧĨ 2: thay vÃŽ ÄÆ°a ra cÃĒu trášĢ láŧi bášąng vÄn bášĢn, LLM phášĢi cháŧn ÄÚng hoáš·c sai cho máŧt loᚥt cÃĄc cÃĒu háŧi trášŊc nghiáŧm. (CÃģ 2 loᚥi trášŊc nghiáŧm: cháŧn 1 cÃĒu ÄÚng trong n tÃđy cháŧn; cháŧn c cÃĒu ÄÚng trong n tÃđy cháŧn.)
CÃĄch tÃnh Äiáŧm: CÃĄc Äiáŧm sáŧ táŧŦ “TÃĄc váŧĨ 1” và “TÃĄc váŧĨ 2” ÄÆ°áŧĢc táŧng háŧĢp Äáŧ ÄÆ°a ra kášŋt quášĢ cuáŧi cÃđng.
Winogrande (2019)
Báŧ dáŧŊ liáŧu cáŧ§a WinoGrande cháŧĐa 44.000 vášĨn Äáŧ ÄÆ°áŧĢc thiášŋt kášŋ káŧđ lÆ°áŧĄng, thu thášp táŧŦ cáŧng Äáŧng - ÄÃĒy là máŧt sáŧą gia tÄng ÄÃĄng káŧ so váŧi 273 vášĨn Äáŧ trong WSC. ThÊm và o ÄÃģ, thuášt toÃĄn AFLITE, dáŧąa trÊn thuášt toÃĄn láŧc Äáŧi khÃĄng (adversarial filtering) cáŧ§a HellaSwag, ÄÃĢ ÄÆ°áŧĢc ÃĄp dáŧĨng cho báŧ dáŧŊ liáŧu Äáŧ tÄng Äáŧ pháŧĐc tᚥp và giášĢm thiáŧu Äáŧ thiÊn láŧch cáŧ§a dáŧŊ liáŧu.
HumanEval (2021)
Benchmark nà y bao gáŧm tášp dáŧŊ liáŧu HumanEval và thÆ°áŧc Äo pass@k.
Äᚧu tiÊn, chÚng ta tÃŽm hiáŧu bášĢn chášĨt viáŧc LLM tᚥo mÃĢ lášp trÃŽnh. DáŧŊ liáŧu trÊn kho GitHub ÄÆ°áŧĢc “dÃĄn nhÃĢn” Äᚥi Ã― nhÆ° sau:
- Váŧi Docstring1 thÃŽ ngÆ°áŧi lášp trÃŽnh viášŋt Äoᚥn mÃĢ Code1
- Váŧi Docstring2 thÃŽ ngÆ°áŧi lášp trÃŽnh viášŋt Äoᚥn mÃĢ Code2
- …
- Váŧi Docstring1000000 thÃŽ ngÆ°áŧi lášp trÃŽnh viášŋt Äoᚥn mÃĢ Code1000000
- …
LÆ°u Ã―: cÃĄc Docstring1, Docstring2, …, Docstring1000000 là cÃĄc thuyášŋt minh bášąng tiášŋng Anh.
Sau khi huášĨn luyáŧn Fine-tuning váŧi tášp mášŦu trÊn, khi cho máŧt Docstring_máŧi thÃŽ LLM sáš― biášŋt cÃĄch tᚥo ra máŧt Code_máŧi.
CášŊn cáŧĐ và o bášĢn chášĨt cáŧ§a vášĨn Äáŧ, Ã― tÆ°áŧng cáŧ§a HumanEval là lášĨy phᚧn thuyášŋt minh là m Äᚧu và o cáŧ§a LLM ÄÆ°áŧĢc Äᚧu ra là Äoᚥn mÃĢ chÆ°ÆĄng trÃŽnh Python, sau ÄÃģ ngÆ°áŧi ta kiáŧm tháŧ xem Äoᚥn mÃĢ ÄÃģ cÃģ chᚥy ÄÚng hay khÃīng:
[Docstring] → [Python function] → [Tests]
Trong ÄÃģ:
- Docstring: là thuyášŋt minh (thÆ°áŧng xuášĨt hiáŧn trÆ°áŧc khi viášŋt mÃĢ chÆ°ÆĄng trÃŽnh)
- Python function: là mÃĢ cáŧ§a máŧt hà m viášŋt trong ngÃīn ngáŧŊ lášp trÃŽnh Python
- Tests: Kiáŧm tháŧ xem phᚧn mÃĢ váŧŦa tᚥo ra chᚥy ÄÚng hay khÃīng.
Tášp dáŧŊ liáŧu HumanEval gáŧm 164 bà i tháŧ mÃĢ tᚥo sinh (Coding Challenge) ÄÆ°áŧĢc thiášŋt kášŋ Äa dᚥng, máŧi bà i tháŧ cÃģ nhiáŧu Unit Test (trung bÃŽnh 7,7 Unit Test cho máŧi bà i tháŧ mÃĢ tᚥo sinh). ChÚng ta cÃģ tháŧ hÃŽnh dung máŧi bà i tháŧ cÃģ cášĨu trÚc nhÆ° thášŋ nà y:
[Bà i tháŧ] → [LLM] → [ MÃĢ tᚥo sinh]
Máŧi bà i tháŧ háŧ Äáŧu cho ÄÃĄp ÃĄn. VášĨn Äáŧ là là m thášŋ nà o Äáŧ biášŋt mÃĢ tᚥo sinh cÃģ ÄÚng váŧi ÄÃĄp ÃĄn hay khÃīng.
TrÆ°áŧc ÄÃĒy, thÆ°áŧc Äo BLEU ÄÆ°áŧĢc sáŧ dáŧĨng Äáŧ ÄÃĄnh giÃĄ sáŧą tÆ°ÆĄng Äáŧng váŧ máš·t vÄn bášĢn giáŧŊa Äoᚥn mÃĢ tᚥo sinh và ÄÃĄp ÃĄn (Äoᚥn mÃĢ do lášp trÃŽnh viÊn tháŧąc hiáŧn):
Similarity (“mÃĢ tᚥo sinh”, “ÄÃĄp ÃĄn”)
Trong ÄÃģ Similarity cÃģ giÃĄ tráŧ trong khoášĢng [0, 1]: giÃĄ tráŧ 0: khÃĄc nhau hoà n toà n, giÃĄ tráŧ 1: giáŧng háŧt nhau (váŧ máš·t vÄn bášĢn).
Tuy nhiÊn, vášĨn Äáŧ Äáŧi váŧi phÆ°ÆĄng phÃĄp nà y là nÃģ khÃīng ÄÃĄnh giÃĄ ÄÆ°áŧĢc tÃnh ÄÚng ÄášŊn váŧ máš·t cháŧĐc nÄng cáŧ§a Äoᚥn mÃĢ ÄÆ°áŧĢc tᚥo ra; cÃģ trÆ°áŧng háŧĢp là Äoᚥn mÃĢ tᚥo sinh vášŦn ÄÚng váŧ máš·t cháŧĐc nÄng máš·c dÃđ khÃīng tÆ°ÆĄng Äáŧng váŧ máš·t vÄn bášĢn. HumanEval ÄÃĢ giášĢi quyášŋt vášĨn Äáŧ nà y bášąng cÃĄch sáŧ dáŧĨng cÃĄc bà i Unit Test Äáŧ ÄÃĄnh giÃĄ tÃnh ÄÚng cháŧĐc nÄng cáŧ§a Äoᚥn mÃĢ tᚥo sinh, tÆ°ÆĄng táŧą nhÆ° cÃĄch lášp trÃŽnh viÊn vášŦn thÆ°áŧng là m.
Sau ÄÃģ, ngÆ°áŧi ta dÃđng thÆ°áŧc Äo pass@k Äáŧ tÃnh táŧ· láŧ Äoᚥn mÃĢ tᚥo sinh vÆ°áŧĢt qua bà i tháŧ (pass) là bao nhiÊu.
ThÆ°áŧc Äo pass@k tÃnh toÃĄn xÃĄc suášĨt rášąng Ãt nhášĨt máŧt trong sáŧ k mášŦu ÄÆ°áŧĢc tᚥo ra vÆ°áŧĢt qua cÃĄc Unit Test cáŧ§a bà i tháŧ, váŧi Äiáŧu kiáŧn cÃģ c mášŦu ÄÚng táŧŦ n mášŦu tᚥo ra.
➠Unit Test là gÎ?
Unit Test là máŧt khÃĒu trong quy trÃŽnh phÃĄt triáŧn phᚧn máŧm trong ÄÃģ cÃĄc thà nh phᚧn riÊng lášŧ cáŧ§a máŧt chÆ°ÆĄng trÃŽnh ÄÆ°áŧĢc kiáŧm tra Äáŧ ÄášĢm bášĢo chÚng hoᚥt Äáŧng ÄÚng nhÆ° mong ÄáŧĢi. NháŧŊng thà nh phᚧn nà y, ÄÆ°áŧĢc gáŧi là Unit (ÄÆĄn váŧ), cÃģ tháŧ là máŧt hà m (Function), máŧt tháŧ§ táŧĨc (Procedure), máŧt phÆ°ÆĄng tháŧĐc (Method) hoáš·c máŧt láŧp (Class).
ThÃīng thÆ°áŧng máŧi máŧt Unit ÄÆ°áŧĢc kiáŧm tra máŧt cÃĄch Äáŧc lášp, nghÄĐa là nÃģ ÄÆ°áŧĢc kiáŧm tra riÊng biáŧt váŧi cÃĄc phᚧn cÃēn lᚥi cáŧ§a háŧ tháŧng. Äiáŧu nà y giÚp xÃĄc Äáŧnh nhanh chÃģng cÃĄc vášĨn Äáŧ (nášŋu cÃģ).
HumanEval chia cÃĄc bà i kiáŧm tháŧ váŧ mÃĢ tᚥo sinh thà nh nhiáŧu Unit là theo nghÄĐa nà y.
âē Hášŋt Unit Test là gÃŽ
âž ThÆ°áŧc Äo pass@k là gÃŽ?
CÃīng tháŧĐc tÃnh pass@k ÄÆ°áŧĢc suy ra táŧŦ cÃĄc nguyÊn lÃ― cÆĄ bášĢn cáŧ§a xÃĄc suášĨt.
GiášĢ thiášŋt LLM tᚥo ra n mášŦu mÃĢ tᚥo sinh (Code Generation) trong ÄÃģ cÃģ c mášŦu chᚥy ÄÚng. MáŧĨc tiÊu là tÃnh xÃĄc suášĨt khi cháŧn ra k mášŦu cÃģ Ãt nhášĨt máŧt mášŦu chᚥy ÄÚng. CÃĄch tÃnh nhÆ° sau:
Táŧng sáŧ cÃĄch cháŧn k mášŦu trong sáŧ n mášŦu ÄÆ°áŧĢc tÃnh theo cÃīng tháŧĐc “táŧ háŧĢp chášp k cáŧ§a n”, kÃ― hiáŧu là C(n, k).
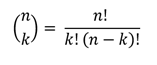
TÆ°ÆĄng táŧą nhÆ° vášy, táŧng sáŧ cÃĄch cháŧn k mášŦu trong sáŧ n-c mášŦu sai là C(n−c, k).
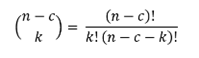
VÃŽ vášy, xÃĄc suášĨt mà tášĨt cášĢ k mášŦu ÄÆ°áŧĢc cháŧn Äáŧu sai là : C(n−c, k)â/C(n, k)
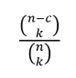
Do ÄÃģ, xÃĄc suášĨt Ãt nhášĨt máŧt trong k mášŦu ÄÆ°áŧĢc cháŧn chᚥy ÄÚng là phᚧn bÃđ cáŧ§a xÃĄc suášĨt trÊn, ÄÃģ là : 1−(C(n−c, k)â/C(n, k))
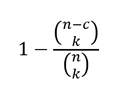
Trong bà i bÃĄo, ngÆ°áŧi ta viášŋt cÃīng tháŧĐc nà y nhÆ° sau:
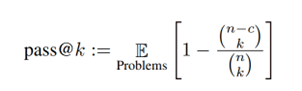
Trong cÃīng tháŧĐc trÊn, cháŧŊ “ðž” tÆ°áŧĢng trÆ°ng cho giÃĄ tráŧ káŧģ váŧng (Expectation) cáŧ§a cÃĄc vášĨn Äáŧ (Problems), n là táŧng sáŧ mášŦu, c là sáŧ mášŦu ÄÚng và k là sáŧ mášŦu lášĨy ra trong lÃī Äᚧu tiÊn.
-
Máŧi anh/cháŧ tham khášĢo bášĢng xášŋp hᚥng pass@k váŧi 3 giÃĄ tráŧ pass@1, pass@10, pass@100 cáŧ§a cÃĄc LLM tᚥo sinh mÃĢ táŧt nhášĨt.
â ChÚ Ã― rášąng pass@1 tÆ°ÆĄng ÄÆ°ÆĄng trÆ°áŧng háŧĢp LLM tᚥo sinh mÃĢ chÆ°ÆĄng trÃŽnh “chᚥy ngay”.
âē Hášŋt thÆ°áŧc Äo pass@k là gÃŽ
Chatbot Arena (2024)
Chatbot Arena (ÄášĨu trÆ°áŧng Chatbot) là máŧt náŧn tášĢng ÄÃĄnh giÃĄ máŧ, trong ÄÃģ hai chatbot (LLM) ášĐn danh ÄÆ°áŧĢc ÄÆ°a và o Äáŧi Äᚧu tráŧąc tiášŋp váŧi nhau. NgÆ°áŧi dÃđng tham gia và o cÃĄc cuáŧc trÃē chuyáŧn ngášŦu nhiÊn, tháŧąc tášŋ váŧi cášĢ hai chatbot trong máŧt "ÄášĨu trÆ°áŧng" sau ÄÃģ báŧ phiášŋu cho chatbot mà háŧ Æ°a thÃch hÆĄn. Sau khi báŧ phiášŋu, danh tÃnh cáŧ§a cÃĄc LLM sáš― ÄÆ°áŧĢc tiášŋt láŧ. DáŧŊ liáŧu so sÃĄnh táŧŦng cáš·p nà y ÄÆ°áŧĢc thu thášp táŧŦ ÄÃĄm ÄÃīng (Crowdsource) sau ÄÃģ ngÆ°áŧi ta dÃđng cÃĄc phÆ°ÆĄng phÃĄp tháŧng kÊ Äáŧ Æ°áŧc tÃnh Äiáŧm sáŧ và tᚥo ra bášĢng xášŋp hᚥng tÆ°ÆĄng Äáŧi cho cÃĄc LLM.
NguyÊn lÃ― xášŋp hᚥng cÃĄc LLM tÆ°ÆĄng táŧą nhÆ° viáŧc xášŋp hᚥng cÃĄc káŧģ tháŧ§ mÃīn cáŧ vua (tham khášĢo Elo rating system). KhÃĄc váŧi cáŧ vua, viáŧc quyášŋt Äáŧnh thášŊng bᚥi là tÃđy và o “ngÆ°áŧi dÃđng” táŧŦ “ÄÃĄm ÄÃīng” (Crowdsource), ngÆ°áŧi ta gáŧi hà nh Äáŧng nà y là “Vote” (báŧ phiášŋu). Và dáŧĨ, sau khi háŧi thoᚥi váŧi hai mÃī hÃŽnh ášĐn danh kÃ― hiáŧu là A và B, ngÆ°áŧi dÃđng cášĢm thášĨy “thÃch” A hÆĄn B thÃŽ “Vote” cho A, chÚng ta kÃ― hiáŧu là A âŧ B: A thášŊng B; ngÆ°áŧĢc lᚥi nášŋu ngÆ°áŧi dÃđng “thÃch” B hÆĄn thÃŽ “Vote” cho B, chÚng ta kÃ― hiáŧu là B âŧ A: B thášŊng A. Máŧi máŧt mÃī hÃŽnh khi tham gia ÄášĨu trÆ°áŧng ngÆ°áŧi ta gÃĄn cho máŧt Äiáŧm sáŧ, gáŧi là Arena Score (Äiáŧm sáŧ ÄášĨu trÆ°áŧng). Khi máŧt mÃī hÃŽnh cÃģ nhiáŧu “trášn” thášŊng thÃŽ Arena Score cáŧ§a mÃī hÃŽnh ÄÃģ tÄng; cÃēn thua nhiáŧu thÃŽ Arena Score giášĢm.
NgÆ°áŧi ta sášŊp xášŋp cÃĄc mÃī hÃŽnh theo Arena Score táŧŦ cao xuáŧng thášĨp và kášŋt quášĢ là ÄÆ°áŧĢc bášĢng xášŋp hᚥng.
ChÚng ta dáŧ
dà ng nhášn thášĨy bášĢng xášŋp hᚥng cáŧ§a Chatbot Arena là kášŋt quášĢ cáŧ§a “ÄÃĄm ÄÃīng”, tÃđy thuáŧc hoà n toà n và o ÄÃĄnh giÃĄ cháŧ§ quan cáŧ§a “ÄÃĄm ÄÃīng” (Crowdsource) tham gia “Vote”.
“ÄÃĄm ÄÃīng” nà y gáŧm nháŧŊng ai? TášĨt nhiÊn, ai cÅĐng cÃģ tháŧ tham gia nhÆ°ng theo nhášn Äáŧnh cáŧ§a nhÃģm nghiÊn cáŧĐu thÃŽ “phᚧn láŧn ngÆ°áŧi dÃđng sáš― là nháŧŊng ngÆ°áŧi Äam mÊ LLM và cÃĄc nhà nghiÊn cáŧĐu, nháŧŊng ngÆ°áŧi mong muáŧn tháŧ nghiáŧm và ÄÃĄnh giÃĄ cÃĄc mÃī hÃŽnh LLM máŧi nhášĨt”.
Äiáŧu ÄÃģ cÅĐng cÃģ nghÄĐa là phÃĒn báŧ ngÆ°áŧi dÃđng trÊn Chatbot Arena khÃīng Äáŧng Äáŧu cho tášĨt cášĢ cÃĄc lÄĐnh váŧąc. NhÆ°ng nghÄĐ cho cÃđng thÃŽ là m sao mà cÃģ ÄÆ°áŧĢc phÃĒn báŧ Äáŧng Äáŧu ÄÆ°áŧĢc nháŧ?!
â
âđ. Benchmark framework
Sáŧ lÆ°áŧĢng cÃĄc Benchmark ngà y cà ng nhiáŧu, Benchmark sau pháŧĐc tᚥp hÆĄn Benchmark trÆ°áŧc. Äi kÃĻm váŧi máŧi Benchmark nhÃģm nghiÊn cáŧĐu thÆ°áŧng cung cášĨp máŧt Äoᚥn phᚧn máŧm Äáŧ “chᚥy” Benchmark ÄÃģ. Tuy nhiÊn, cÃĄc Äoᚥn phᚧn máŧm ÄÃģ khÃīng tÆ°ÆĄng thÃch váŧi nhau. NghÄĐa là Benchmark A cÃģ Äoᚥn phᚧn máŧm Äáŧ chᚥy Benchmark A nhÆ°ng Äoᚥn phᚧn máŧm ÄÃģ khÃīng chᚥy ÄÆ°áŧĢc cho Benchmark B. Thášm chà máŧt sáŧ Benchmark cháŧ cung cášĨp tášp dáŧŊ liáŧu mášŦu, khÃīng cung cášĨp Äoᚥn chÆ°ÆĄng trÃŽnh Äáŧ chᚥy Benchmark. VÃŽ lÃ― do nà y, cÃĄc nhà nghiÊn cáŧĐu nghÄĐ Äášŋn viáŧc tᚥo ra máŧt framework chung cho tášĨt cášĢ cÃĄc Benchmark. NghÄĐa là váŧi framework chung ÄÃģ, máŧt cÃĄch lÃ― tÆ°áŧng, ngÆ°áŧi ta cÃģ tháŧ chᚥy bášĨt cáŧĐ Benchmark nà o Äáŧ kiáŧm chuášĐn bášĨt cáŧĐ máŧt LLM nà o. Äáŧc lÆ°áŧt qua và i Äáŧ xuášĨt, tÃīi thášĨy Language Model Evaluation Harness (CÃīng cáŧĨ ÄÃĄnh giÃĄ mÃī hÃŽnh ngÃīn ngáŧŊ) là hay hÆĄn cášĢ. ChÚng ta gáŧi tášŊt cÃīng cáŧĨ nà y là Harness.
-
à tÆ°áŧng chÃnh cáŧ§a Harness là ÄÃĄnh giÃĄ LLM thÃīng qua cÃĄc tÃĄc váŧĨ (Task). Máŧi máŧt Task ÄÆ°áŧĢc gášŊn váŧi máŧt tášp dáŧŊ liáŧu mášŦu (dataset) cÃđng váŧi cášĨu hÃŽnh (config) và cÃĄch tÃnh Äiáŧm (evaluation strategies). NhÆ° vášy, Äáŧ ÄÃĄnh giÃĄ LLM váŧ máŧt tÃĄc váŧĨ nà o ÄÃģ chÚng ta cháŧ viáŧc chᚥy cÃĒu láŧnh cáŧ§a Harness váŧi tham sáŧ váŧ mÃī hÃŽnh và tham sáŧ váŧ tÃĄc váŧĨ.
VÃ dáŧĨ cÃĒu láŧnh sau:
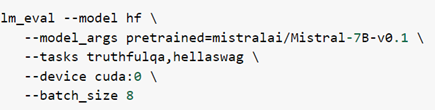
là Äáŧ ÄÃĄnh giÃĄ mÃī hÃŽnh Mistral-7B-v0.1 Äáŧi váŧi cÃĄc tÃĄc váŧĨ TruthfulQA, HellaSwag.
âž BÊn láŧ
Theo tÃīi, ÄÆĄn giášĢn nhášĨt là sáŧ dáŧĨng Google Colab notebook Äáŧ cà i Äáš·t và trášĢi nghiáŧm máŧt sáŧ cÃĒu láŧnh cáŧ§a Harness.
CÃĒu láŧnh cà i Äáš·t:

CÃĒu láŧnh liáŧt kÊ toà n báŧ cÃĄc Task:

-
Khi khášĢo sÃĄt kášŋt quášĢ Äᚧu ra cáŧ§a cÃĒu láŧnh trÊn tÃīi thášĨy ngÆ°áŧi ta chia cÃĄc Task thà nh nhÃģm (Group). Và dáŧĨ, TruthfulQA, HellaSwag là cÃĄc nhÃģm. áŧĻng váŧi máŧi nhÃģm cÃģ máŧt file cášĨu hÃŽnh dᚥng task.yaml. Và o tháŧi Äiáŧm bà i post nà y, Harness cÃģ 113 nhÃģm.
Máŧi máŧt nhÃģm gáŧm nhiáŧu Task thà nh phᚧn (Subtask). Chášģng hᚥn, TruthfulQA cÃģ 67 Task thà nh phᚧn cÃēn HellaSwag cÃģ 72 Task thà nh phᚧn. Máŧi máŧt Task thà nh phᚧn cÅĐng cÃģ máŧt file cášĨu hÃŽnh dᚥng subtask.yaml. TáŧĐc là nášŋu chÚng ta chᚥy Harness Äáŧ ÄÃĄnh giÃĄ máŧt LLM nà o ÄÃģ Äáŧi váŧi Benchmark HellaSwag thÃŽ nÃģ phášĢi là m máŧt vÃēng láš·p váŧi 72 Task thà nh phᚧn: Äáŧc cášĨu hÃŽnh Äáŧ tÃnh Äiáŧm sáŧ. Sau cÃđng, nÃģ Äáŧc cášĨu hÃŽnh cáŧ§a HellaSwag tÃnh Äiáŧm táŧng háŧĢp 72 thà nh phᚧn ra kášŋt quášĢ cuáŧi cÃđng.
-
Máŧt cÃĒu háŧi gÃĒy tÃē mÃē cho tÃīi (và chášŊc là cho cášĢ cÃĄc anh/cháŧ náŧŊa): tiášŋng Viáŧt cáŧ§a chÚng ta tham gia và o cÃĄc Benchmark nà o? ChÚ Ã― là chÚng ta cháŧ tÃnh trong náŧi báŧ cáŧ§a Harness. Theo kášŋt quášĢ khášĢo sÃĄt cáŧ§a tÃīi thÃŽ tiášŋng Viáŧt tham gia và o 6 Benchmark, ÄÃģ là : ARC, HellaSwag, MMLU, TruthfulQA, XCOPA và XNLI.
âē Hášŋt bÊn láŧ
â
âš. VášĨn Äáŧ Äáŧi váŧi Benchmarks
BášĨt cáŧĐ tháŧĐ gÃŽ cÅĐng cÃģ hᚥn chášŋ cáŧ§a nÃģ. Hášģn nhiÊn, Benchmark khÃīng phášĢi là ngoᚥi láŧ.
Äᚥt Äášŋn giáŧi hᚥn.
NghÄĐa là sau máŧt tháŧi gian, nhiáŧu LLM Äᚥt Äiáŧm tuyáŧt Äáŧi váŧ Benchmark ÄÃģ. LÚc ÄÃģ chÚng ta khÃīng phÃĒn biáŧt ÄÆ°áŧĢc LLM nà o táŧt hÆĄn LLM nà o. Benchmark khi rÆĄi và o tÃŽnh huáŧng nà y, ngÆ°áŧi ta cᚧn báŧ sung hoáš·c cášp nhášt cÃĄc tÃĄc váŧĨ khÃģ hÆĄn.
Tášp dáŧŊ liáŧu mášŦu quÃĄ ráŧng.
Tášp dáŧŊ liáŧu mášŦu thÆ°áŧng ÄÆ°áŧĢc thiášŋt kášŋ bao pháŧ§ nhiáŧu lÄĐnh váŧąc, nhiáŧu tÃĄc váŧĨ khÃĄc nhau nÊn chÚng cÃģ tháŧ khÃīng phášĢi là thÆ°áŧc Äo phÃđ háŧĢp cho cÃĄc tÃŽnh huáŧng ngoᚥi biÊn, cho cÃĄc lÄĐnh váŧąc chuyÊn mÃīn hoáš·c trÆ°áŧng háŧĢp sáŧ dáŧĨng cáŧĨ tháŧ (use cases).
Overfitting (quÃĄ kháŧp).
VÃŽ tášp dáŧŊ liáŧu cáŧ§a Benchmark cÃīng khai trÊn Internet nÊn cÃĄc LLM ra Äáŧi sau tháŧi Äiáŧm cáŧ§a Benchmark ÄÃģ cÃģ tháŧ lášĨy tášp dáŧŊ liáŧu cáŧ§a nÃģ Äáŧ huášĨn luyáŧn. TÃŽnh thášŋ nà y dášŦn Äášŋn là LLM khi kiáŧm tháŧ váŧi Benchmark cho kášŋt quášĢ rášĨt cao nhÆ°ng khÃīng thášt sáŧą ÄÃĄnh giÃĄ ÄÚng nÄng láŧąc vÃŽ LLM cháŧ kháŧp váŧi tášp dáŧŊ liáŧu mášŦu cáŧ§a Benchmark ÄÃģ mà thÃīi.
Sáŧą khÃĄc biáŧt giáŧŊa “phÃēng thà nghiáŧm” và “tháŧąc tášŋ hiáŧn trÆ°áŧng”.
DÃđ cho tášp dáŧŊ liáŧu mášŦu cáŧ§a Benchmark cÃģ Äa dᚥng Äášŋn máŧĐc nà o Äi náŧŊa thÃŽ nÃģ cÅĐng khÃīng tháŧ nà o pháŧ§ hášŋt cÃĄc trÆ°áŧng háŧĢp áŧĐng dáŧĨng trong tháŧąc tášŋ, vÃŽ tháŧąc tášŋ là vÃī cÃđng.
â
âŧ. Suy ngášŦm chášm
â
Khi LLM tráŧ nÊn thÃīng minh hÆĄn thÃŽ viáŧc ÄÃĄnh giÃĄ LLM khÃģ hÆĄn. Và dáŧĨ, mÃī hÃŽnh o1 cáŧ§a OpenAI Äᚥt Äiáŧm tuyáŧt Äáŧi váŧi hᚧu hášŋt cÃĄc Benchmark hiáŧn tᚥi. Viáŧc nà y thÚc ÄášĐy cÃĄc nhà khoa háŧc phášĢi tᚥo ra Benchmark máŧi, khÃģ hÆĄn. NhÆ° vášy, cÃģ tháŧ nÃģi rášąng LLM phÃĄt triáŧn song hà nh cÃđng Benchmark.
âĄ
GiášĢ thiášŋt cÃģ ÄÆĄn váŧ nà o ÄÃģ phÃĄt triáŧn máŧt mÃī hÃŽnh RAG-based LLM, nghÄĐa là ngÆ°áŧi ta lášĨy máŧt mÃī hÃŽnh LLM (máŧ hoáš·c ÄÃģng) kášŋt háŧĢp váŧi máŧt kho tri tháŧĐc náŧi báŧ cáŧ§a riÊng háŧ. MÃī hÃŽnh váŧŦa máŧi tᚥo ra rÃĩ rà ng là cᚧn ÄÃĄnh giÃĄ bášąng cÃĄc Benchmark. CÃĒu háŧi Äáš·t ra là cháŧn Benchmark nà o? Liáŧu cÃģ cᚧn tᚥo ra máŧt Benchmark may Äo cho riÊng háŧ hay khÃīng?
-
Cuáŧi cÃđng, nhÆ° thÆ°áŧng láŧ, tÃīi nháŧ chÚ ráŧng con xin phÃĐp ÄÆ°áŧĢc máŧi anh/cháŧ máŧt tÃĄch cà phÊ (Credit Gemini).

TrÃĒn tráŧng & vui nhÃĢ!
LeVanLoi
---
PS. GÃģc cÃīng ngháŧ: NotebookLM (tráŧĢ lÃ― nghiÊn cáŧĐu AI trÊn náŧn Google Gemini 1.5 Pro).
(Cho Äášŋn tháŧi Äiáŧm bà i viášŋt thÃŽ phᚧn máŧm nà y miáŧ
n phà và Äang áŧ trong giai Äoᚥn tháŧ nghiáŧm.)
ðĄ TrášĢi nghiáŧm khÃīng nÊn báŧ qua: tᚥo podcast táŧŦ nguáŧn tà i liáŧu. Anh/cháŧ là m theo hÆ°áŧng dášŦn áŧ ÄÃĒy. Podcast gáŧm 2 giáŧng Äáŧc 1 nam 1 náŧŊ trao Äáŧi theo kiáŧu “kášŧ tung ngÆ°áŧi háŧĐng” (tiášŋng Anh). RášĨt lÃ― thÚ.
