Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Machine Learning.
- Tính thời sự: Tháng 04/2022.
- Thời gian đọc: đọc ý chính: 5 phút, đọc hết: 20 phút.
~
⓪ Đề dẫn
Tôi chủ quan cho rằng hầu hết anh/chị trên diễn đàn này đã ít nhất một lần sử dụng Google để tìm ảnh (hoặc biểu tượng) trên Internet, sau đó chèn chúng vào một loại tài liệu nào đó (luận văn, bài giảng, tranh biện, …), nhằm thuyết trình, giảng bài, truyền đạt kiến thức một cách trực quan, sinh động.
Ví dụ:
- Bật tìm kiếm Google (https://www.google.com/),
- Chuyển sang tìm kiếm ảnh (https://www.google.com.vn/imghp?hl=en&ogbl)
- Và gõ cụm từ “a koala in a forest” (gấu túi ở trong rừng)
Thế là chúng ta được “vô số” ảnh, tranh, biểu tượng, … tương ứng với caption “a koala in a forest”. Tôi xin phép lấy một ảnh của kết quả tìm kiếm nhằm làm cho cốc cà phê của anh/chị thêm phần thơm dịu.

Koala, facts and photos
nationalgeographic.com
-
Chủ đề tôi xin phép đàm luận cùng anh/chị lần này là Text-to-Image Generation (Tạo hình ảnh từ văn bản). Nói theo một cách khác cho dễ hình dung: chúng ta “vẽ” tranh, ảnh - không phải bằng bút vẽ - mà chúng ta “vẽ” bằng cách đưa vào một “đoạn văn”. Trước mắt, “đoạn văn” cần được viết bằng tiếng Anh. Tất nhiên, chúng ta có thể viết “đoạn văn” bằng tiếng Việt, sau đó chuyển ngữ (dịch máy) sang tiếng Anh và nhập “đoạn văn” cho đầu vào của mô hình và kết quả là mô hình sẽ cho ra một bức tranh. Cái hay là chúng ta có thể “điều chỉnh” bức tranh bằng cách tổ hợp ý tưởng (concept) với thuộc tính (attribute: ví dụ tạo bóng (shadow), phản chiếu (reflection), hoa văn nền (texture), …), và phong cách (style) theo một trường phái nào đấy – ví dụ hiện thực nguyên bản (photorealism) hay trường phái ấn tượng Claude Monet, …
-
Với bản tính tò mò của một ICT_VNer, chắc hẳn chúng ta sẽ đặt câu hỏi: làm thế nào mà họ có thể cho ra kết quả “tài tình” như thế?
Tuy ví dụ được lấy từ công cụ tìm kiếm Google (để anh/chị dễ dàng trải nghiệm) nhưng toàn bộ tài liệu tham chiếu cho bài post tôi lại lấy từ OpenAI. Cụ thể, các bài báo đó là:
- Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- Zero-Shot Text-to-Image Generation (DALL·E)
- Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL·E 2)
Để súc tích, ngắn gọn, chúng ta thống nhất gọi tên các bài báo là CLIP (bài 1), DALL·E (bài 2) và DALL·E 2 (bài 3).
Việc tiếp theo của tôi đơn giản chỉ là “đọc hiểu”, “tóm lược” các ý chính để phục vụ anh/chị nhâm nhi cà phê.
🗎→🖼
① Tổng quan
Trước khi đi vào phần mang tính kỹ thuật chi tiết, tôi xin tóm lược các mô hình - với một vài ví dụ - trích ra từ các bài báo.
⁇ CLIP làm gì?
CLIP kết nối “văn bản” với “ảnh”. Đại ý là “với văn bản như này thì sẽ được ảnh như kia”. “Văn bản” và “ảnh” đều là các thực thể có thật trên Internet, được kết nối lại với nhau. “Văn bản” của CLIP có dạng “a photo of a [object]” (ảnh của [vật]). Ảnh của CLIP thường là một vật (object) hoặc một ngữ cảnh.
Ví dụ:
a photo of a airplane.

Nguồn.
🗎→🖼
⁇ DALL·E làm gì?
DALL·E tạo “ảnh” từ “văn bản”. Chú ý rằng “ảnh” là do DALL·E “tạo ra”, là ảnh đã được biến đổi từ các ảnh thật.
Ví dụ:
Nếu đưa vào mô hình DALL·E “đoạn văn” thì chúng ta thu được “ảnh”. Xem các ví dụ sau (được lấy từ bài báo):
Đoạn văn:
“a professional high quality illustration of a giraffe turtle chimera. A giraffe imitating a turtle. A giraffe made of turtle.”
(một minh họa chất lượng cao chuyên nghiệp của con vật ảo huyền rùa hươu cao cổ. một con hươu cao cổ bắt chước một con rùa. một con hươu cao cổ làm bằng rùa.)
Tạo ra hình ảnh:

Nguồn.
~
Đoạn văn:
“the exact same cat on the top as a sketch on the bottom.”
(cùng một con mèo ở phía trên cùng với bản phác họa ở phía dưới.)
Tạo ra hình ảnh:

Nguồn.
🗎→🖼
⁇ DALL·E 2 làm gì?
DALL·E 2 có thể tạo ra các hình ảnh và nghệ thuật hiện thực nguyên bản từ mô tả của “đoạn văn”. Mô hình này có thể tổ hợp các khái niệm (concept), thuộc tính (attribute) và phong cách (style).
Ví dụ:
Đoạn văn:
An astronaut lounging in a tropical resort in space in a vaporwave style.
(Một phi hành gia thư giãn trong một khu nghỉ mát nhiệt đới trong không gian theo phong cách sóng hơi)
Tạo ra hình ảnh:

Nguồn.
~
Đoạn văn:
An astronaut lounging in a tropical resort in space as pixel art.
(Một phi hành gia thư giãn trong một khu nghỉ mát nhiệt đới trong không gian dưới dạng nghệ thuật pixel.)
Tạo ra hình ảnh:

Nguồn.
~
Đoạn văn:
An astronaut lounging in a tropical resort in space in a photorealistic style.
(Một phi hành gia thư giãn trong một khu nghỉ mát nhiệt đới trong không gian theo phong cách ảnh thực.)
Tạo ra hình ảnh:

Nguồn.
🗎→🖼
⁇ Mối quan hệ giữa các bài báo CLIP, DALL·E và DALL·E 2 là như thế nào?
Các bài báo CLIP và DALL·E được đăng vào tháng 1/2021, gần như đồng thời. Vì vậy, hai bài báo này độc lập với nhau.
DALL·E 2 được đăng vào tháng 4/2022. Nói về tên bài báo thì DALL·E 2 là phiên bản sau của DALL·E. Tuy nhiên, DALL·E 2 không nâng cấp từ DALL·E mà tiếp cận theo một cách hoàn toàn mới. Trong cách tiếp cận mới này, DALL·E 2 lồng ghép mô hình CLIP vào mô hình của mình.
-
Tiếp theo, mời anh/chị cùng tham khảo cách tiếp cận của từng bài báo. Các phần ②, ③, ④ có nhiều chi tiết kỹ thuật – nếu anh/chị ngại thì có thể bỏ qua và đọc tiếp phần ⑤.
🗎→🖼
② CLIP
CLIP là viết tắt của cụm từ Contrastive Language–Image Pre-training. Mục tiêu của CLIP là kết nối “văn bản” – “ảnh”.
Ý tưởng chính của CLIP là tận dụng ảnh có sẵn trên Internet. Trong kho ảnh khổng lồ đó, có một số ảnh có mô tả (caption). Từ đó, sau khi lọc ảnh có mô tả, người ta có một kho dữ liệu dưới dạng (ảnh, văn bản). “Văn bản” ở đây chính là caption - mô tả của ảnh (bằng tiếng Anh). Tất nhiên, cách mô tả khi post lên Internet thì mỗi người ghi một kiểu, chả theo một quy chuẩn nào cả. (Đây là điểm khác biệt so với những kho ảnh đã được cộng đồng Machine Learning dựng sẵn như ImageNet, CIFAR-100, CAFAR-10, MNIST.)
CLIP thực hiện theo các bước sau.
- Bước 1: Huấn luyện Pre-training với tập dữ liệu mẫu 400 triệu cặp (ảnh, văn bản).
- Bước 2: Phân lớp văn bản thành 32,768 lớp, đồng nhất mô tả theo dạng “a photo of a [object]”.
- Bước 3: Khi đưa một ảnh vào (ví dụ: a dog), mô hình sẽ “dự đoán” và cho kết quả theo dạng “a photo of a dog”.
Mời anh/chị tham khảo minh họa ý tưởng trong hình vẽ dưới đây. Hình vẽ này tôi sao chép từ bài báo.
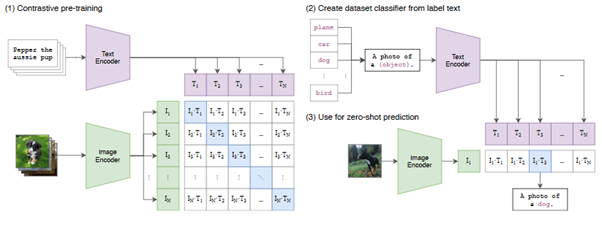
Cách tiếp cận của CLIP: mã hóa văn bản và ảnh để ghép cặp (văn bản, ảnh).
Tiếp theo, CLIP biến thành bộ phân lớp (gồm 32,768 lớp) dưới dạng “a photo of a [object]”.
CLIP có thể “nhận dạng” ảnh: ảnh thuộc loại nào trong số 32,768 loại đã được thiết lập.
Nguồn.
~
Trong một chừng mực nào đó, chúng ta có thể coi CLIP biết nhận dạng ảnh một vật thể (object). Anh/chị lưu ý rằng nhận dạng ảnh về bản chất là bài toán phân loại ảnh. Chỉ có điều là khi nhận dạng thì số loại ảnh không có một giới hạn cụ thể. Trong trường hợp của CLIP, số loại ảnh là 32,768 – cũng có thể coi là “không có giới hạn” 😊.
~
⁇ Điểm tiếp theo, hẳn nhiều anh/chị tò mò về kỹ thuật đứng đằng sau mô hình này là gì. Người ta đã thu thập được 400 triệu cặp ghép (ảnh, văn bản). Nhưng vấn đề là làm thế nào đo được “độ tương thích” giữa ảnh và văn bản? “Ảnh” này gắn với “văn bản” nào?
Chìa khóa của giải pháp là người ta sử dụng embedding (nhúng). Để giúp anh/chị đỡ phải đi lục tìm khái niệm này trên mạng, tôi nôm na tóm tắt thế này: người ta biến mọi thứ thành một điểm trong không gian số thực N chiều: ℝN. Việc này đồng nghĩa với ánh xạ từ tập X vào không gian ℝN: X → ℝN. Xin lưu ý với anh/chị, các bài báo họ dùng từ vector. Nghĩa là một điểm trong không gian ℝN có hướng xuất phát từ tâm của không gian ℝN và mũi tên chỉ đến tọa độ của điểm đó. Hai điểm trong không gian này được gọi là tương tự theo hệ số similarity (0 ≤ similarity ≤ 1). Khi hai điểm trùng khớp nhau (hoặc 2 vector song song), chúng có similarity = 1.
CLIP mã hóa tất cả ảnh và văn bản thành các điểm trong không gian này nhưng sắp xếp theo cặp (ảnh, văn bản). Mục tiêu là sau khi huấn luyện mô hình thì các cặp điểm (ảnh, mô tả thực sự) phải ở sát nhau, nghĩa là chúng phải có similarity gần bằng 1. Ngược lại, các cặp điểm (ảnh, mô tả không liên quan) phải ở cách xa nhau, nghĩa là chúng có similarity gần bằng 0.
Sau khi huấn luyện 400 triệu cặp (ảnh, văn bản) mà họ đã thu thập thì kết quả không gian này được biến đổi như thế nào? Chúng ta phân biệt 2 trường hợp:
- Các cặp điểm (“ảnh”, “văn bản”) trùng khớp nhau (similarity=1) thì “văn bản” chính là mô tả của “ảnh”.
- Nếu điểm “ảnh” không có “văn bản” nào trùng khớp thì làm thế nào? Chúng ta đo “khoảng cách” từ điểm “ảnh” tới tất cả các điểm “văn bản” và chọn điểm “văn bản” nào có khoảng cách ngắn nhất (tương ứng với similarity lớn nhất). Đó chính là “văn bản” sát nhất cho mô tả của ảnh. Lưu ý rằng CLIP sử dụng phép đo khoảng cách bằng hàm cosine, đo góc từ tâm của 2 điểm. Nghĩa là hai điểm càng gần nhau thì giá trị cosine càng lớn, gần bằng 1.
~
⁇ Câu hỏi tò mò tiếp theo: huấn luyện mô hình này như thế nào? Chúng ta lưu ý rằng dữ liệu huấn luyện là cặp (ảnh, văn bản). Giả thiết có N cặp (ảnh, văn bản) thì số dữ liệu bung ra để huấn luyện là N x N = N2 cặp (xem minh họa ở dưới đây).
[(ảnh1, văn bản1), (ảnh1, văn bản2), …, (ảnh1, văn bảnN)]
…
[(ảnhi, văn bản1), … (ảnhi, văn bảni), …, (ảnhi, văn bảnN)]
…
[(ảnhN, văn bản1), … (ảnhN, văn bảni), …, (ảnhN, văn bảnN)]
-
Trong số N2 cặp này, chỉ có N cặp là đúng ảnh đúng mô tả (in đậm trong minh họa trên), còn lại là các cặp ghép trộn (số này là N2-N) (in mờ trong minh họa trên). Dữ liệu đưa vào đối với N cặp là đúng ảnh đúng mô tả thì hàm mục tiêu phải Maximize(similarity) tiến tới 1, còn đối với N2-N cặp còn lại thì cần có công thức cho hàm mục tiêu Minimize(similarity) tiến về 0. Như vậy là có đồng thời 2 mục tiêu trái ngược nhau trong cùng một batch dữ liệu. Phương pháp huấn luyện này được đặt tên là Contrastive Representation Learning. Từ “Contrastive” tạm dịch là “Trái ngược”. Cái thách thức lớn nhất trong huấn luyện theo phương pháp này là lựa chọn hàm mục tiêu: hàm này phải có giá trị Max đối với lớp đối tượng “tương tự nhau” nhưng đồng thời phải cho giá trị Min đối với lớp đối tượng “bất liên quan”. Đây là phương pháp huấn luyện được cộng đồng nghiên cứu Machine Learning đặc biệt quân tâm gần đây.
~
Trở lại với tên của bài báo: Contrastive Language–Image Pre-training. Chúng đã thấy ý nghĩa của từ Contrastive (đây là từ đại diện cho phương pháp huấn luyện Contrastive Representation Learning), cặp từ Language – Image (ý nói là kết nối văn bản - ảnh). Từ cuối Pre-training ngụ ý rằng CLIP là Pre-training trong cách tiếp cận 2 bước: Pre-training và Fine-tuning. Đại ý của cách tiếp cận này như sau:
Pre-training: huấn luyện mô hình với tập dữ liệu cực lớn. Trong trường hợp của CLIP, tập dữ liệu này là 400 triệu cặp (ảnh, văn bản). Pre-training thường được huấn luyện task-agnostic (độc lập tác vụ). Nghĩa là mô hình được huấn luyện không bị bó hẹp vào một tác vụ cụ thể nào cả. Đây là mô hình lớn (Upstream – thượng nguồn), tổng quan, sẵn sàng cho việc chuyển giao cho các tác vụ nhỏ. Mô hình cơ sở này cung cấp cho chúng ta lời giải tổng quát.
Fine-tuning: Đối với một tác vụ cụ thể, người ta tinh chỉnh trọng số mô hình cơ sở bằng một tập nhỏ dữ liệu mẫu.
-
Liên quan đến Fine-tuning, mô hình GPT-3 đưa thêm 3 khái niệm nữa:
Few-Shot (FS): Trường hợp này mô hình cần K mẫu demo nhưng không được phép điều chỉnh trọng số. K nằm trong khoảng 10-100. K mẫu này dùng để làm gì? Chỉ là để cho máy “nhận dạng tác vụ”!
One-Shot (1S): Tương tự như Few-Shot nhưng trong trường hợp này, máy chỉ cần 1 mẫu để “nhận dạng tác vụ”.
Zero-Shot (0S): Không cần mẫu demo mà vẫn biết được tác vụ!
-
Trong bài báo, CLIP có đề cập đến Zero-Shot. Một cách nôm na: không cần huấn luyện tiếp (tức là không cần đến bước Fine-tuning), CLIP đã có thể cho kết quả luôn. Zero-shot của CLIP là bài toán phân loại ảnh: khi đưa một ảnh vào thì mô hình sẽ cho biết ảnh này thuộc lớp nào trong số 32,768 lớp.
-
⚠ Chú ý về mặt kỹ thuật, điểm đặc biệt của CLIP là xử lý ảnh thông qua một lãnh địa hoàn toàn khác: ngôn ngữ.
🗎→🖼
③ DALL·E
Vì sao tên mô hình là DALL·E trong lúc tên của bài báo là Zero-Shot Text-to-Image Generation (tạo ảnh “tức thì” từ văn bản)? Theo bài blog của OpenAI: “Chúng tôi quyết định đặt tên cho mô hình của mình bằng cách sử dụng từ ghép của nghệ sĩ Salvador Dalí và WALL·E (tên một bộ phim của hãng Pixar)”. Căn cứ theo tra cứu trên Internet thì nghệ sĩ Salvador Dalí được coi như một trong những họa sĩ có ảnh hưởng lớn nhất trong thế kỷ 20 với phong cách siêu thực. Còn WALL·E (Rô-bốt biết yêu) là một bộ phim hoạt hình đồ họa vi tính, thể loại khoa học viễn tưởng và lãng mạn, do Pixar Animation Studios sản xuất năm 2008.
-
Tương tự CLIP, DALL·E lấy dữ liệu là ảnh có mô tả trên Internet. Số lượng tập mẫu của DALL·E là 250 triệu cặp (văn bản, ảnh). Khác với CLIP, DALL·E là một mô hình thu nhỏ của GPT-3: GPT-3 có 175 tỷ tham số còn DALL·E có 12 tỷ tham số.
Chúng ta biết rằng GPT-3 huấn luyện dữ liệu ngôn ngữ có tính chất tự động tiếp diễn (autoregressive): x1, x2, …, xn, xn+1… trong đó xn+1 = FP(x1, x2, …, xn). Tức là từ sau cùng (xn+1) được suy diễn một cách xác suất từ tập hợp các từ trước đó (tương tự như khi chúng ta đọc hiểu văn bản: chúng ta hiểu nghĩa từ tiếp theo nhờ chúng ta đã hiểu nghĩa các từ trước đó).
Thế còn DALL·E huấn luyện thế nào? Một cách giản lược, dòng dữ liệu “chảy” như sau:
(văn bản 1, ảnh 1)
(văn bản 2, ảnh 2)
…
Chúng ta có thể hiểu một cách nôm na về dữ liệu huấn luyện như sau:
với “văn bản 1” như này thì sẽ có “ảnh 1” như kia,
với “văn bản 2” như này thì sẽ có “ảnh 2” như kia,
…
Người ta huấn luyện mô hình với 250 triệu cặp (văn bản, ảnh) như vậy. Sau khi mô hình được huấn luyện xong, nếu chúng đưa đầu vào là “văn bản x” thì mô hình sẽ cho ra “ảnh y”. Tức là mô hình tạo ảnh (đầu ra “ảnh y”) từ văn bản (đầu vào “văn bản x”). Đơn giản là vậy 😊!
~
Chú ý rằng DALL·E là mô hình thu nhỏ của GPT-3 - mà GPT-3 sử dụng dữ liệu huấn luyện là loại dữ liệu tự động tiếp diễn (autoregressive): x1, x2, …, xn, xn+1… trong đó xn+1 = FP(x1, x2, …, xn). Nghĩa là dòng dữ liệu này không phân biệt đâu là văn bản, đâu là ảnh. Vì vậy, người ta bắt buộc phải mã hóa văn bản và mã hóa ảnh để biến chúng thành cùng một loại dữ liệu đồng nhất.
Trước hết chúng ta cùng tò mò về cách họ mã hóa (nén) văn bản và ảnh.
Mã hóa văn bản.
Văn bản được viết từ các ký tự nên việc nén văn bản đồng nghĩa với việc nén số các ký tự tạo thành văn bản. DALL·E sử dụng kỹ thuật nén BPE (Byte pair encoding). Nếu anh/chị là “dân lập trình” và tò mò về mặt kỹ thuật, anh chị có thể tham khảo bài báo “A New Algorithm for Data Compression” (1994). Đây là một cách đơn giản để nén số các ký tự:
- Thay thế các cặp ký tự liền kề (c1c2) lặp nhiều lần nhất (n lần) bằng một ký tự mới (k1). Bằng thao tác này chúng ta giảm số ký tự của văn bản bằng số lần lặp (n). Lý do? Văn bản gốc có n cặp ký tự liền kề. Nghĩa là số ký tự của n cặp này là 2*n. Còn số ký tự sau khi được thay thế là n. Như vậy, số ký tự giảm xuống là (2*n)-n = n. Sau mỗi lần thay thế, người ta thêm vào một dòng trong “bảng tra cứu” dạng k1 ⇨ c1c2. Mục đích của việc này là để giải mã sau này.
- Thuật toán lặp lại bước này cho đến khi không còn cặp ký tự liền kề nào lặp lại trong dãy văn bản hoặc không còn chỗ để tạo ra ký tự mới.
Việc giải mã được thực hiện bằng vòng lặp đi từ đáy “bảng tra cứu” lên đầu bảng: thay thế các ký tự (kl) bằng các cặp (cicj).
Chú ý rằng GPT-3 cũng sử dụng kỹ thuật nén BPE. Như vậy có thể nói DALL·E “tương thích” với GPT-3 về cách nén dữ liệu văn bản.
Mã hóa ảnh.
Sau khi thu thập ảnh, người ta dùng một phần mềm cho bước tiền xử lý: biến tất cả các ảnh về độ phân giải 256x256 RGB (rộng: 256 pixel, cao 256 pixel, mỗi pixel là một điểm màu tổ hợp từ 3 màu R: Red, G: Green, B: Blue). Ảnh này tiếp tục được nén xuống độ phân giải 32x32 bằng mạng nơ ron autoencoder (tự mã hóa). Từ ảnh nén này, sau đó người ta mới trộn với văn bản (đã mã hóa theo kỹ thuật BPE) và đưa vào Transformer để huấn luyện.
Bên lề ▼
Để giúp anh/chị đỡ mất công lục tìm khái niệm autoencoder trên mạng, tôi xin tóm lược một cách nôm na như sau: autoencoder là mạng nơ ron “nén” đầu vào X vào một khối h, sau đó “bung” khối h thành X’ có cùng kích cỡ với X (xem ảnh dưới đây).
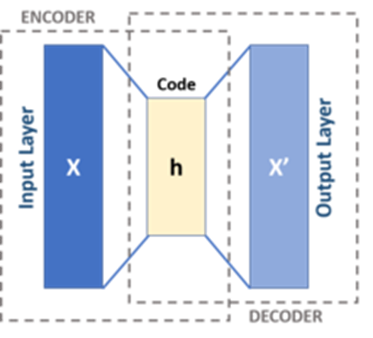
Lược đồ của một Autoencoder cơ bản.
Nguồn.
~
Chúng ta có cảm giác là X’ sẽ giống hệt X? Không hẳn. Lưu ý có 2 yếu tố làm cho X’ khác với X:
1. khối h có kích cỡ bé hơn X và
2. đây là một mạng nơ-ron nên trọng số (weight) của mạng biến đổi theo tập mẫu dữ liệu dùng để huấn luyện. Vì vậy, X’ được tạo ra không đơn thuần chỉ phụ thuộc vào X mà còn phụ thuộc vào tập mẫu dữ liệu.
Bên lề ▲
-
Trộn văn bản với ảnh.
Tiếp theo, chúng ta xem cách họ trộn văn bản với ảnh như thế nào? Cặp (văn bản, ảnh) được mã hóa thành một chuỗi 1280 token: 256 ký tự (đã được mã hóa BPE) nối với 1024 logit (32x32) từ ảnh đã được mã hóa bằng mạng nơ ron autoencoder. Chú ý rằng vì autoencoder là mạng nơ-ron nên người ta phải huấn luyện mạng này (dữ liệu là 250 triệu ảnh).
Dữ liệu là một chuỗi các đoạn 1280 token như sau:
[256 ký tự BPE (văn bản), 1024 logit từ autoencoder (ảnh)],
[256 ký tự BPE (văn bản), 1024 logit từ autoencoder (ảnh)],
…
Trong các đoạn chứa token ở trên thì số logit luôn luôn được phủ đầy (do độ phân giải 32x32) nhưng dãy ký tự BPE thì nhiều nhất là 256 nhưng phần lớn trường hợp con số này nhỏ hơn 256. Trong trường hợp không phủ đầy, người ta bắt buộc phải điền vào các chỗ trống đó bằng một giá trị đặc biệt, ký hiệu là −∞ (âm vô cùng).
-
Thử nghiệm.
Nhóm tác giả bất ngờ với kết quả thử nghiệm 😊! Tức là khi họ thử nghiệm, họ không ngờ kết quả lại được “hay” như thế, ngoài cả mong đợi (xem các ví dụ minh họa dưới đây).
Đoạn văn:
a tapir made of accordion. a tapir with the texture of an accordion.
(một con heo vòi làm bằng đàn accordion. một con heo vòi với kết cấu của một chiếc đàn accordion.)
Tạo ra ảnh:

Nguồn.
~
Đoạn văn:
an illustration of a baby hedgehog in a christmas sweater walking a dog
(minh họa một con nhím con trong chiếc áo len Giáng sinh đang dắt chó)
Tạo ra ảnh:

Nguồn.
~
⁇ Cái gì đã tạo ra “magic”?
Có lẽ nhiều anh/chị, cũng giống như tôi, đặt câu hỏi: cái gì đã tạo ra được hiệu ứng kỳ lạ như vậy? Theo ý kiến cá nhân tôi thì đây là kết quả “biến dị” của việc huấn luyện mô hình. Họ huấn luyện theo 2 giai đoạn:
Giai đoạn 1: chỉ huấn luyện autoencoder. Lưu ý độ nén: ảnh 256x256 RGB nén về 32x32 RGB. Lúc này, autoencoder có thể “bung” ra ảnh kết quả tổ hợp của các ảnh bất kỳ trong số 250 triệu ảnh!
Giai đoạn 2: huấn luyện ghép văn bản với ảnh (đoạn văn 256 ký tự ghép với 1024 logit). Chú ý là giai đoạn này autoencoder đã được huấn luyện, được “đóng băng”. Dữ liệu ghép vào với văn bản từ autoencoder lấy từ lớp trước lớp cuối, sát với lớp đầu ra (logit).
Sau khi huấn luyện xong, autoencoder sẽ “bung” tùy theo tổ hợp từ (cụm từ) từ “đoạn văn” đầu vào.
Có lẽ đó là cái “magic” của DALL·E chăng?!
🗎→🖼
④ DALL·E 2
Bài báo DALL·E đăng tháng 2/2021 còn bài DALL·E 2 đăng vào tháng 4/2022. Rõ ràng DALL·E 2 muốn nâng cấp cách tạo ra ảnh từ văn bản nhưng với cách tiếp cận mới. Phần này tôi muốn đàm luận cùng anh/chị về cách tiếp cận của DALL·E 2: có gì đặc biệt, có gì giống và khác so với DALL·E.
Mời anh/chị tham khảo minh họa ý tưởng trong hình vẽ dưới đây. Hình vẽ này tôi sao chép từ bài báo.
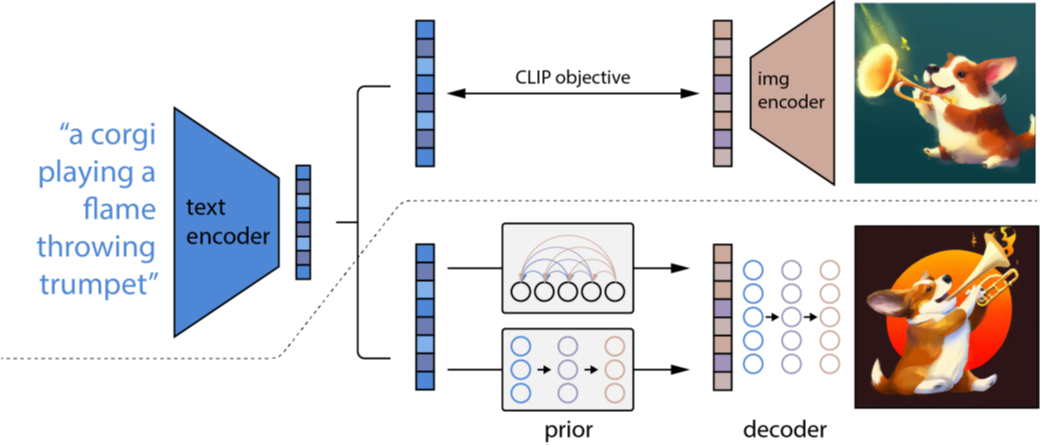
Nguồn.
Tổng quan về DALL·E 2 (các tác giả bài báo gọi quy trình này là unCLIP – nghĩa là đảo ngược CLIP).
-
Giai đoạn 1: Phía trên đường chấm chấm, mô tả quá trình huấn luyện CLIP, kết quả là cặp (“văn bản nhúng”, “hình ảnh nhúng”).
Giai đoạn 2: Bên dưới đường chấm chấm, mô tả quy trình tạo hình ảnh từ văn bản:
Đầu tiên, mạng Prior lấy mẫu dữ liệu đầu vào là “văn bản nhúng” và đầu ra là “hình ảnh nhúng” (từ CLIP).
Tiếp theo, mạng Decoder lấy mẫu dữ liệu đầu vào là “hình ảnh nhúng” và đầu ra là ảnh gốc.
Chú ý rằng trong quá trình huấn luyện giai đoạn 2, mạng CLIP đã được huấn luyện, được “đóng băng” một cách cố định.
-
⁇ Nét tương đồng giữ DALL·E và DALL·E 2 là gì?
Chúng ta dễ dàng nhận thấy điểm chung của DALL·E và DALL·E 2:
- Cả hai mô hình này đều huấn luyện theo 2 giai đoạn.
- Giai đoạn 1 là để mã hóa (encode).
- Khi huấn luyện giai đoạn 2, mạng đã huấn luyện trong giai đoạn 1 được cố định (đóng băng). Đầu vào và đầu ra của mạng trong giai đoạn 1 được lấy để trộn vào mẫu dữ liệu dùng cho huấn luyện giai đoạn 2.
-
⁇ DALL·E 2 có gì đặc biệt?
Chắc nhiều anh/chị sẽ thắc mắc: hẳn là DALL·E 2 phải có gì đặc biệt chứ? Chả nhẽ hơn 1 năm thiết kế, huấn luyện mô hình “đắt đỏ” như thế mà không có cái gì mới sao 😊 !?
Trả lời: Hẳn là phải có điểm khác biệt rồi. Cái mà họ muốn là tìm cách “biến đổi” ảnh đầu ra một cách chủ động, chứ không phải thụ động như mô hình DALL·E. (Vì sao nói DALL·E là thụ động? Vì các tác giả của mô hình DALL·E còn không ngờ DALL·E tạo ra ảnh “hay” thế 😊.)
-
Quay trở lại với ý tưởng chính của DALL·E 2. Tập dữ liệu mẫu mà DALL·E 2 huấn luyện là cặp (x, y), trong đó x là ảnh, còn y là mô tả (caption) của ảnh x.
Giai đoạn 1. Sau khi huấn luyện giai đoạn 1 (CLIP), khi đưa cặp (x, y) vào thì mô hình CLIP sẽ cho ra (zi, zt) trong đó zi là “nhúng” của x và zt là “nhúng” của y. Một cách tượng trưng, chúng ta có thể hình dung như sau:
(x, y) → CLIP → (zi, zt).
Đến giai đoạn 2:
Mạng Prior huấn luyện gì? Cặp dữ liệu huấn luyện của Prior là (zi, y). Nghĩa là nếu cho đầu vào mô tả (caption) y thì mạng sẽ suy diễn một cách xác suất được zi (là nhúng của ảnh x). Viết theo công thức xác suất về mạng Prior: P (zi | y). Một cách tượng trưng, chúng ta có thể hình dung như sau:
y → Prior → zi
Mạng Decoder huấn luyện gì? Giải mã x từ zi và y. Viết theo công thức xác suất về mạng Decoder: P(x | zi, y). Một cách tượng trưng, chúng ta có thể hình dung như sau:
(zi, y) → Decoder → x
-
Mấu chốt để mô hình có thể biến đổi ảnh đầu ra nằm ở mạng Decoder. Decoder chứa cặp biến ẩn (zi, xT). Chúng ta đã biết zi là nhúng của ảnh x. Thế xT là gì vậy? Vì mạng Decoder được huấn luyện theo Diffusion Model (mô hình khuếch tán) nên xT chính là ảnh x được làm nhiễu sau T bước. Có thể coi zi là yếu tố lõi của ảnh x, còn xT là yếu tố biến dị của ảnh.
Bên lề ▼
Diffusion Model (Mô hình khuếch tán) là gì?
Để giúp anh/chị đỡ phải đi lục tìm trên mạng khái niệm Diffusion Model, tôi mạnh dạn “diễn nôm” để chúng ta nhanh chóng nắm bắt ý tưởng.
Giả thiết chúng ta có một loạt ảnh gia đình chụp từ những năm 1960 và theo thời gian ảnh bị mờ lỗ chỗ, hỏng nhiều phần. Bây giờ chúng ta muốn phục hồi các ảnh này cho thật rõ thì làm thế nào? Có cách gì để thiết kế một mô hình mạng nơ-ron để làm việc này không?
Chúng ta hình dung là ảnh gốc bị phá hủy theo quy luật nào đó, tỷ lệ theo thời gian T, như hình vẽ minh họa sau đây:

Sửa đổi từ nguồn.
Vấn đề là chúng ta muốn phục hồi ảnh gốc (X0) từ ảnh đã bị hủy hoại (XT) như hình vẽ minh họa sau đây:

Sửa đổi từ nguồn.
Nếu chúng ta chỉ có mấy cái ảnh cũ đã bị hủy theo thời gian thì … đành chịu. Nhưng nếu chúng ta có hàng triệu ảnh rõ nét tương tự như ảnh của gia đình thì việc tái lập rõ nét ảnh cũ là hoàn toàn có thể. Cách làm là thế nào?
Ý tưởng của Diffusion Model là lấy tập hợp các ảnh rõ nét đó, huấn luyện mạng bằng cách chủ động tạo nhiễu và tái lập ảnh gốc từ các ảnh nhiễu. Sau khi mô hình được huấn luyện xong, khi chúng ta đưa đầu vào là ảnh cũ (ảnh XT trong hình vẽ trên) thì mô hình sẽ cho ra ảnh rõ nét từ lúc chưa bị hỏng (ảnh X0 trong hình vẽ trên).
Rất “magic”, đúng không ạ?! Vấn đề là phải tìm ra hàm mục tiêu (hoặc hàm tương tự thay thế hàm mục tiêu) để học (learning) được cách phục chế từng bước (trong tổng số T bước), truy trở lại ảnh gốc.
Khi đọc các bài báo về Diffusion Model tôi xin giới thiệu với anh chị 2 bài, nếu anh/chị có thời gian tham khảo.
- Có lẽ bài đầu tiên đề cập về Diffusion Model là bài: Deep Unsupervised Learning using Nonequilibrium Thermodynamics.
- Bài hiện nay được nhiều người trích dẫn là bài: Denoising Diffusion Probabilistic Models.
⚠ Cảnh báo: Các bài báo trên có rất nhiều công thức, hằng đẳng thức toán học phức tạp 😊!
Bên lề ▲
Câu hỏi tiếp theo: ⁇ Họ điều khiển ảnh đầu ra bằng cách nào? Căn cứ theo bài báo, họ thực hiện thao tác điều khiển ảnh chủ yếu theo 3 cách sau đây.
Biến đổi hình dạng và xoay hướng ảnh.

Nguồn.
Ảnh được mã hóa bởi CLIP và giải mã bằng Decoder. Các biến thể bảo tồn thông tin “cốt lõi” như sự hiện diện của đồng hồ trong tranh (tranh bên trái ở trên) và các nét chồng lên nhau trong logo (tranh bên phải ở trên), cũng như các yếu tố phong cách như tính siêu thực trong tranh và độ chuyển màu trong logo, đồng thời thay đổi các chi tiết không “cốt lõi”.
-
Sử dụng phép nội suy đối với cặp ảnh.

Nguồn.
Nội suy cặp ảnh nhúng từ CLIP và giải mã bằng Decoder. Người ta cố định ảnh nguồn (ảnh trái và ảnh phải). Các ảnh ở giữa là pha trộn (nội suy) từ hai ảnh nguồn.
-
Sử dụng phép toán text diffs (“hiệu số” văn bản)

Nguồn.
Đầu tiên người thực hiện nội suy cặp ảnh nhúng (giống như phép nội suy). Tiếp theo người ta lấy “hiệu số” của cặp “mô tả” (caption). Chú ý rằng không gian nhúng, vì ℝN là không gian số thực nên nếu 2 điểm (a, b) nằm trên cùng một trục thì người ta dễ dàng tìm ra hiệu số của chúng |a-b|. Các ảnh ở giữa 2 ảnh trong minh họa trên có “mô tả” (caption) nằm trong khoảng (a, b).
-
⑤ Trải nghiệm với DALL·E mini
Nếu anh/chị đọc các bài báo như DALL·E, DALL·E 2, hay các bài trước đây như GPT-3 thì anh/chị dễ dàng nhận ra có một nét chung. Nét chung đó là: sau khi diễn giải một hồi về các kỹ nghệ tân tiến nhất (state-of-the-art), sau khi liệt kê hàng loạt các so sánh, đánh giá a, b, c, … đến phần độc giả mong đợi nhất là trải nghiệm thì tất cả đều nói “chúng tôi phải đóng mã nguồn” và “không cấp đường link trải nghiệm” 😊! Lý do phổ biến là người ta lo ngại về tác động “xấu” của mô hình lên xã hội như gây định kiến chia rẽ, thù hận, phân biệt sắc tộc, tôn giáo, … Nói tóm lại là chúng ta không có cơ hội trải nghiệm.
-
Tuy nhiên, đối với DALL·E, có một ngoại lệ. Đó là DALL·E mini.
Ngày 21/4/2022, Boris Dayma và cộng sự cho ra đời một phiên bản DALL·E thu nhỏ có tên là DALL·E mini trên trang GitHub. Ngày 17/5/2022, Boris Dayma tải mô hình thu nhỏ này lên trang Hugging Face, tại đây. Nguyên lý của DALL·E mini cũng giống như DALL·E: khi cho đầu vào là một đoạn văn (bằng tiếng Anh) thì DALL·E mini cho ra hình ảnh “ứng” với đoạn văn đó. Căn cứ theo bình luận của một số chuyên gia trên mạng thì ảnh của DALL·E mini không có chất lượng tốt bằng DALL·E, nhưng theo tôi thì vẫn rất OK.
Nói thêm về bản upload của Boris Dayma trên trang Hugging Face. Trang này vẫn im ắng cho đến ngày 4/6/2022 khi có một “thread” (dãy các tweets) trên Twitter đăng giới thiệu DALL·E thì mọi người bắt đầu đổ xô vào thử và làm cho trang này thường lâm vào tình trạng quá tải.
-
Rất may là tôi đã có dịp trải nghiệm và xin giới thiệu cùng anh/chị một vài kết quả của trải nghiệm thú vị này.
-
1. Chúng ta ai cũng biết họa sỹ Bùi Xuân Phái nổi tiếng với các bức tranh phố cổ Hà Nội. Tôi “thử” xem DALL·E có “biết” họa sỹ Bùi Xuân Phái với các nét vẽ của ông không bằng cách đưa vào prompt “Ha Noi painted by bui xuan phai” và kết quả là:

“Ha Noi painted by bui xuan phai”
Trông cũng “được” đấy chứ, đúng không anh/chị?!
-
2. Tiếp theo, tôi “nhờ” ông vẽ phố ở Huế (“Hue painted by bui xuan phai”), theo phong cách phố cổ Hà Nội và được kết quả như sau:

“Hue painted by bui xuan phai”
Anh/chị nào đã từng ở Huế có nhận ra phố “Phái” xưa bên sông Hương núi Ngự không 😊?
-
3. Tiếp theo, tôi tiếp tục nhờ ông vẽ cùng phong cách với phố ở Sài Gòn (“Sai Gon painted by bui xuan phai”):

“Sai Gon painted by bui xuan phai”
Có anh/chị nào nhận ra “Sài Gòn” xưa qua nét bút của Bùi Xuân Phái không?!
-
4. Tiếp tục trải nghiệm, lần này tôi nhờ họa sỹ Paul Gauguin. Tôi tin chắc là rất nhiều anh/chị biết họa sỹ người Pháp này nổi tiếng với phong cách vẽ theo trường phái ấn tượng các thiếu nữ trên đảo Tahiti. Tôi “nhờ” ông vẽ áo dài Việt Nam (“Ao dai painted by gauguin”):

“Ao dai painted by gauguin”
Có “ấn tượng” không anh/chị?
-
5. Có lẽ rất nhiều người trong số chúng ta biết đến họa sỹ người Hà Lan Vincent van Gogh, với bức họa lừng danh “Starry Night”, và nhiều bức tranh đồng quê êm dịu như “Road in Etten” (Đường ở Etten), “Garden with Fence” (Vườn có hàng rào), “House with Thatched Roofs” (Nhà có mái tranh), “Café Terrace at Night” (Quán cà phê ngoài sân vào ban đêm), … Lần này, tôi nhờ họa sỹ vẽ Chùa Một cột ở Hà Nội theo phong cách của ông (“Chua mot cot painted by van gogh”):

“Chua mot cot painted by van gogh”
Nhìn các bức tranh này thì cảm nhận của anh/chị thế nào? Có thấy cái “magic” của DALL·E không ạ?
-
6. Tiếp theo, tôi “nhờ” danh họa người Tây Ban Nha là Pablo Picasso vẽ “Chùa Thiên Mụ” ở Huế theo trường phái lập thể (“Chua thien mu painted by picasso”):

“Chua thien mu painted by picasso”
Trong tập hợp 9 bức tranh ở trên, kết quả có lẽ ảnh hưởng bởi cụm từ “Chùa Thiên Mụ” gồm “Chùa” và “Thiên Mụ” (Bà Tiên) hợp lại. Vậy nên, bộ ảnh gồm 6 ảnh “Chùa” và 3 ảnh “Bà Tiên”.
-
7. Cuối cùng, tôi nhờ danh họa siêu thực Salvador Dalí vẽ Nhà thờ Đức Bà ở Sài Gòn (“nha tho duc ba sai gon painted by Salvador Dalí”):

“nha tho duc ba sai gon painted by Salvador Dalí”
Wa! Thực sự ấn tượng, đúng không ạ !?
-
Báo cáo với anh/chị, tổng thời gian tôi “vẽ” 7 “bộ tranh” trên là khoảng 1 tiếng đồng hồ. Một người chẳng biết gì về hội họa mà lại có thể “sản xuất” ra được ngần ấy “tác phẩm” chỉ trong khoảng thời gian chưa đến 60 phút thì đúng là “siêu tưởng”! Mà đấy là tôi gõ phím theo phương pháp “mổ cò” đấy, chứ với anh/chị nào “múa phím” 10 ngón thì không biết số “tác phẩm” sẽ là bao nhiêu 😊.
-
Để kết thúc bài viết, chú thỏ “ấn tượng” thay tôi xin phép mời anh/chị một tách cà phê.

