~
Để giúp anh/chị quyết định có đọc tiếp hay không, tôi xin phép cung cấp các thông tin liên quan đến bài post này như sau:
- Chủ đề: Machine Learning,
- Tính thời sự: Tháng 01/2024
- Thời gian đọc: 6 phút, kể cả thời gian uống cà phê (uống cà phê xong là đọc xong)
▒
Ⓐ. Đề dẫn
Chúng ta biết rằng LLM (Large Language Model) về bản chất là một mô hình Pre-training. Nghĩa là các trọng số của mô hình (weights) ở dạng tĩnh (static). Thông thường LLM được cập nhật thông tin đến một thời điểm T nào đó. Nếu có truy vấn (prompt) sau thời điểm T thì LLM, nếu nhận biết rằng câu truy vấn liên quan đến thông tin sau thời điểm T, nó sẽ nhã nhặn từ chối đưa ra hồi đáp (response). Nếu nó không nhận ra rằng câu truy vấn có thông tin chưa được cập nhật (sau thời điểm T) thì nó đưa ra hồi đáp ảo giác (hallucination). Lấy ví dụ, ChatGPT 3.5 được cập nhật thông tin công khai trên Internet cho đến tháng 1 năm 2022. Nghĩa là T = tháng 1/2022.
Để minh họa, tôi đặt câu hỏi “Quốc gia nào vô địch FIFA World Cup?” đối với các LLM là ChatGPT 3.5 (OpenAI), Copilot (Microsoft) và Gemini 1.0 (Google). Đây là các câu trả lời (chỉ trích dẫn phần liên quan trực tiếp đến câu hỏi):
- ChatGPT 3.5: Hiện tại, danh hiệu vô địch FIFA World Cup thuộc về đội tuyển quốc gia của Ý. Đội tuyển Ý vô địch FIFA World Cup lần thứ hai sau khi đánh bại đội tuyển Anh trong trận chung kết tại FIFA World Cup 2022 được tổ chức tại Qatar. 😊
- Copilot: Theo kết quả tìm kiếm trên web, quốc gia vô địch FIFA World Cup gần nhất là Argentina, đội đã đánh bại Brazil với tỷ số 1-0 trong trận chung kết tại Qatar vào năm 2022. 😊
- Gemini 1.0: Đội tuyển vô địch FIFA World Cup gần đây nhất là Argentina. Họ đã chiến thắng Pháp 4-2 trong trận chung kết World Cup 2022 được tổ chức tại Qatar.
Dễ dàng nhận thấy cả ChatGPT 3.5 lẫn Copilot đều “phán lung tung”, chỉ mỗi Gemini 1.0 là chấp nhận được.
-
Qua minh họa ở trên, chúng ta nhận thấy hallucination là một vấn đề đau đầu của LLM. Để giảm thiểu hallucination người ta không thể cứ huấn luyện LLM liên tục được vì việc Pre-training cực kỳ tốn kém. Tất nhiên, các nhà khoa học Machine Learning không ngồi yên – người ta cần tìm giải pháp cho vấn đề này. Một cách ngẫu nhiên thú vị, hóa ra vấn đề này đã được đề cập từ ngày 22/5/2020 thông qua bài báo “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” của nhóm tác giả Patrick Lewis và cộng sự. Chú ý rằng vào thời điểm đó ChatGPT chưa tồn tại (ChatGPT ra đời vào tháng 11/2022). RAG là viết tắt của cụm từ tiếng Anh: “Retrieval Augmented Generation”.
Bên lề ▼ Dịch cụm từ “Retrieval Augmented Generation”?
Trước hết, theo ý kiến cá nhân tôi, chúng ta nên để nguyên viết tắt RAG, vì khi nói đến RAG thì cộng đồng Machine Learning – Ta lẫn Tây – ai cũng hiểu. Ở đây tôi chỉ muốn nhàn đàm thêm về việc dịch và hiểu bản chất của cụm từ. Ngay như tác giả của bài báo, Patrick Lewis, cho biết “We definitely would have put more thought into the name had we known our work would become so widespread”. Tức là tác giả cũng bất ngờ về công trình của họ được sử dụng phổ biến như hiện nay. Nếu biết trước có ngày như thế họ có thể đã nghĩ ra một cái tên hay hơn! 😊
Với vô số các công cụ dịch có sẵn trên Internet, anh/chị dễ dàng dịch cụm từ này với “vô số” kết quả. Tuy nhiên, để địch cho nghĩa sát với nội hàm của phương pháp RAG thì câu chuyện không đơn giản. Với rất nhiều các “ứng viên”, tôi lọc ra một tùy chọn: “Tạo sinh văn bản tích hợp với tra cứu thông tin”. Tất nhiên, tùy chọn này còn lâu mới được gọi là “dịch hay” nhưng khá sát với nội hàm của RAG.
Bên lề ▲
-
Ý tưởng RAG trong bài báo gốc như sau:
Khi nhận được câu truy vấn (Query), đầu tiên người ta dùng câu truy vấn như một cụm từ để tìm kiếm trong kho thông tin ngoài (chẳng hạn như Wikipedia) được K documents gần nghĩa nhất (gọi là Top K, trong một kho thông tin có thể lên đến hàng triệu, hàng tỷ tài liệu), sau đó ghép K documents này với Query rồi đưa vào để truy vấn LLM:
[Prompt = Query + K documents] → [LLM] → [Answer (Response)]
Ví dụ minh họa:
- Query = “When did the first mammal appear on Earth?”
- RAG trích xuất từ Wikipedia được các tài liệu liên quan gồm “Mammal”, “History of Earth” và “Evolution of Mammals” ký hiệu là doc1, doc2 và doc3 (K trong trường hợp này = 3).
- Prompt = “When did the first mammal appear on Earth?” + doc1 + doc2 + doc3
trong đó dấu “+” là hàm ghép (concatenate) chuỗi ký tự.
-
Nhóm tác giả gọi giải pháp trên là kết hợp thế mạnh của “open-book” và “closed-book”. “Closed-book” ở đây là LLM (tĩnh, cố định) còn “open-book” là kho thông tin mở, kho thông tin này thường xuyên được cập nhật – ví dụ Wikipedia. Tức là RAG có 2 nguồn tri thức: tri thức từ LLM và tri thức từ nguồn ngoài (“open-book”).
Đấy – ý tưởng chỉ đơn giản thế thôi. 😊
▒
Ⓑ. RAG Framework
Chúng ta hình dung cách thức RAG Framework hoạt động như trong hình vẽ sau:
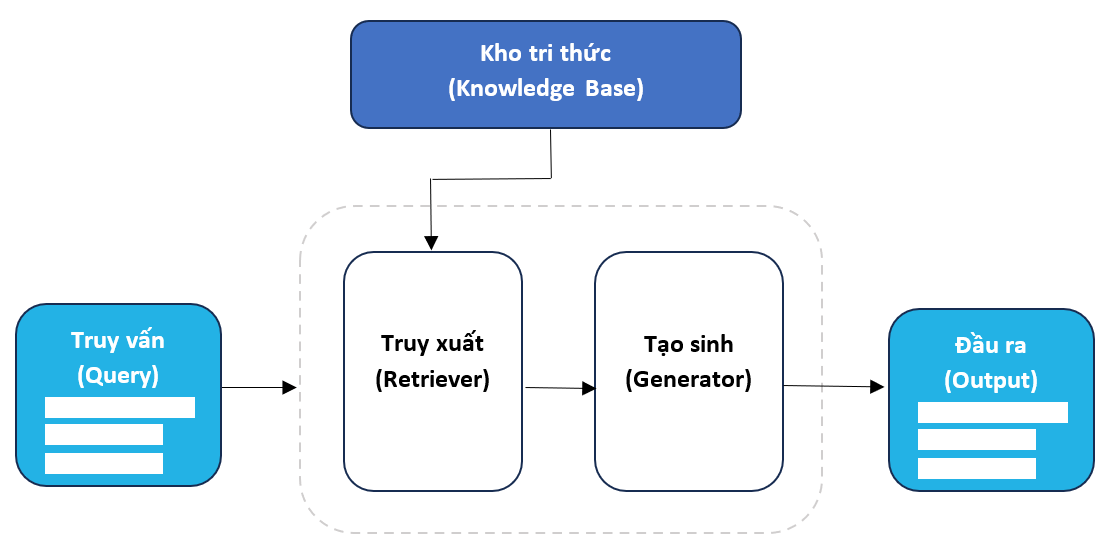
RAG Framework
RAG Framework gồm 2 thành phần chính là khối Truy xuất và Tạo sinh.
- Nhiệm vụ của khối Truy xuất là nhận câu Truy vấn và tìm trong Kho tri thức các thông tin mà nó đánh giá là có mối liên quan nhất với câu truy vấn. Sau đó nó tổ hợp kết quả tìm được với câu truy vấn gốc và biến thành Prompt cho khối Tạo sinh.
- Nhiệm vụ của khối Tạo sinh là đọc Prompt và tạo đầu ra. Nếu khối Tạo sinh là LLM thì việc này là chức năng hiển nhiên của LLM.
Bây giờ nói đến Kho tri thức. Kho này có thể chỉ có vài tài liệu nhưng cũng có thể đến hàng triệu, hàng tỷ tài liệu. Vậy cần có kiến trúc như thế nào để có thể truy xuất nhanh mà vẫn tìm ra được thông tin sát với câu truy vấn? Hiện nay, người ta tổ chức tiền xử lý kho tri thức này theo các bước sau:
Indexing (lập chỉ mục)
Đầu tiên người ta lọc thông tin từ các tài liệu thô (PDF, HTML, Word, Markdown, …) bỏ hết các dữ liệu format, chỉ giữ lại văn bản. Chia các file lớn thành các đoạn văn bản (mục, câu). Các đoạn văn bản được gọi là chunk hay passage.
Embedding (nhúng)
Tiếp theo, người ta nhúng các đoạn văn bản này vào một không gian số thực N chiều. Các từ, cụm từ trong kho tri thức được nhúng vào không gian này và người ta đo độ tương tự theo ngữ nghĩa (semantic similarity). Trong không gian này, các điểm (vector) chứa các từ, cụm từ gần ngữ nghĩa sẽ đứng sát nhau. Chú ý là chúng tương tự ngữ nghĩa (semantic) chứ không phải tương tự chính tả (spelling).
Ý nghĩa của công đoạn này là lúc truy xuất, người ta chỉ việc nhúng câu truy vấn và đo độ tương tự của điểm nhúng này với tất cả các điểm trong kho tri thức. Sau đó, người ta chỉ việc lọc ra K điểm gần với điểm nhúng (truy vấn) nhất. Từ K điểm này họ tra ngược ra được K đoạn văn bản. Và K đoạn văn bản này chính là kết quả của truy xuất.
▒
Ⓒ. Kịch bản ứng dụng (Use Case)
①
Giả thiết rằng một doanh nghiệp nào đó muốn ứng dụng LLM vào công việc của mình, có thể truy xuất thông tin của chính doanh nghiệp đó – các thông tin mà doanh nghiệp không công bố công khai trên Internet. RAG rõ ràng là ứng viên hàng đầu cho việc này: Kho tri thức chính là Kho dữ liệu thông tin riêng của doanh nghiệp. Kho này tập hợp các cơ sở dữ liệu có cấu trúc, các tài liệu phi cấu trúc như các file Word, PDF, HMTL, email, … Cũng giống như Kho tri thức của RAG, Kho dữ liệu thông tin riêng của doanh nghiệp cần được tiền xử lý là Indexing (lập chỉ mục) và Embedding (nhúng). Chúng ta tạm thời đặt tên là RAG Enterprise (Doanh nghiệp) để phân biệt với RAG tổng quát.
RAG Enterprise dùng vào việc gì?
- Dùng trong nội bộ doanh nghiệp: Là một chatbot hiểu tất cả các ngóc ngách của doanh nghiệp. Vì RAG có tích hợp LLM nên chatbot này có đầy đủ các tính năng như tóm tắt nội dung các tài liệu dài, tổng hợp thông tin nội bộ của doanh nghiệp theo chủ đề, phân tích báo cáo tài chính, phân tích xu thế thị trường sản phẩm nội bộ doanh nghiệp, phân tích đối thủ cạnh tranh, phân tích phản hồi khách hàng, … Vì RAG Enterprise dạng này chứa nhiều thông tin của nội bộ doanh nghiệp nên chúng ta đặt tên là RAG Enterprise Internal.
- Dùng cho khách hàng và đối tác: Là một chatbot dùng để giải đáp tất cả các truy vấn liên quan đến sản phẩm và dịch vụ của doanh nghiệp. Vì RAG có tích hợp LLM nên chatbot này có đầy đủ các tính năng như lập hồ sơ sản phẩm/dịch vụ trong nháy mắt, gợi ý sản phẩm căn cứ theo túi tiền của khách hàng, căn cứ theo giới, độ tuổi, … Vì RAG Enterprise này chỉ dùng cho khách hàng và đối tác nên chúng ta đặt tên là RAG Enterprise External.
-
②
Bây giờ chúng ta hình dung một cơ sở giáo dục muốn tạo ra một RAG. Cách tiếp cận tương tự như khi tạo ra RAG Enterprise: Kho tri thức là kho dữ liệu riêng của cơ sở giáo dục này, bao gồm dữ liệu cấu trúc và phi cấu trúc, phần lớn không đăng tải công khai trên các website (và vì vậy các LLM không có thông tin). Chúng ta đặt tên là RAG Edu. Chatbot RAG Edu thường có các chức năng như:
- Thông tin khóa học: Người học có thể hỏi về các khóa học hiện có, chi tiết chương trình, lịch trình, lệ phí và thủ tục đăng ký. Chatbot có thể hướng dẫn họ trong quá trình đăng ký và cung cấp thông tin liên quan để giúp họ đưa ra quyết định tối ưu.
- Khuyến nghị được cá nhân hóa: Dựa trên sở thích, mối quan tâm và lai lịch của người học, chatbot có thể đưa ra lời khuyên về khóa học được cá nhân hóa, định hướng nghề nghiệp, mẹo học và cách tìm học liệu phù hợp với nhu cầu cá nhân đó.
- Quản lý sự kiện: Người học có thể hỏi về các sự kiện, hội thảo, webinar và các buổi đào tạo ngoại khóa. Chatbot có thể hỗ trợ đăng ký sự kiện, gửi lời nhắc và cung cấp thông tin liên quan đến sự kiện như chương trình, diễn giả và chi tiết địa điểm.
- Tác vụ hành chính: Chatbot có thể giúp người học quản lý lịch học, đặt lịch hẹn, xử lý thanh toán và truy cập hồ sơ học tập. Nó có thể tự động hóa các tác vụ thường ngày và hợp lý hóa các quy trình cho cả học viên và giáo viên.
-
③
Lần này người ta áp dụng cùng một cách thức cho một cơ sở y tế. Chúng ta đặt tên là RAG HealthCare. Chức năng chính của chatbot RAG HealthCare là hỗ trợ, chăm sóc y tế đối với các bệnh nhân đến khám, chữa trị tại đây:
- Lên lịch hẹn: Chatbot có thể hỗ trợ bệnh nhân lên lịch hẹn với cơ sở y tế. Nó có thể kiểm tra các khung giờ hẹn, xác nhận cuộc hẹn và gửi lời nhắc cho bệnh nhân.
- Kiểm tra và phân loại triệu chứng: Bệnh nhân có thể mô tả các triệu chứng của họ cho chatbot, sau đó chatbot có thể đưa ra đánh giá ban đầu và đề xuất phân loại dựa trên mức độ nghiêm trọng của các triệu chứng. Nó có thể đề xuất các bước phù hợp tiếp theo, chẳng hạn như đến cơ sở y tế ngay lập tức hoặc lên lịch tư vấn ảo.
- Tư vấn y tế: Chatbot có thể cung cấp thông tin tổng quát, trả lời các câu hỏi liên quan đến sức khỏe bệnh nhân và cung cấp tài nguyên giáo dục về chủ đề sức khỏe. Nó có thể đưa ra các lời khuyên về chăm sóc phòng ngừa, thói quen lối sống lành mạnh, quản lý thuốc và quản lý bệnh tật.
- Nhắc nhở về thuốc: Bệnh nhân có thể nhận được lời nhắc về thuốc và hướng dẫn liều lượng từ chatbot để giúp họ tuân thủ kế hoạch điều trị của mình. Chatbot cũng có thể cung cấp thông tin về việc kê đơn thuốc, tác dụng phụ và tương tác thuốc.
- Tư vấn y tế từ xa: Chatbot có thể hỗ trợ tư vấn ảo giữa bệnh nhân và bác sỹ chăm sóc sức khỏe, cho phép bệnh nhân thảo luận về mối quan tâm về sức khỏe của họ, nhận lời khuyên y tế và yêu cầu đơn thuốc tại nhà.
- Hỗ trợ thanh toán bảo hiểm: Bệnh nhân có thể hỏi về phạm vi bảo hiểm, yêu cầu thanh toán và các tùy chọn thanh toán thông qua chatbot. Nó có thể cung cấp hỗ trợ để hiểu các lợi ích bảo hiểm, xử lý các yêu cầu bồi thường và giải quyết các tranh chấp khi thanh toán.
- Hỗ trợ cấp cứu: Trong tình huống cấp cứu, chatbot có thể hỗ trợ ngay lập tức bằng cách hướng dẫn bệnh nhân những việc cần làm, kết nối họ với các dịch vụ cấp cứu hoặc cung cấp hướng dẫn sơ cứu cho đến khi có trợ giúp.
-
Chú ý: Các thuật ngữ như RAG Enterprise, RAG Enterprise Internal, RAG Enterprise External, RAG Edu, RAG HealthCare là do tôi tự nghĩ ra để nhàn đàm cho vui chứ chả căn cứ vào đâu cả! 😊
▒
Ⓓ. Suy ngẫm chậm
①
Liệu RAG có loại bỏ được ảo giác (hallucination) không? Câu trả lời là: Chưa! ☹
RAG chỉ hạn chế sự xuất hiện của ảo giác chứ chưa thể loại bỏ hoàn toàn. Và có thể là không tồn tại giải pháp nào loại bỏ hoàn toàn được ảo giác. Có thể anh/chị cảm thấy thất vọng về câu trả lời này nhưng suy cho cùng chúng ta vẫn thấy logic của vấn đề. LLM dù khổng lồ đến mấy nhưng chắc chắn là hữu hạn. Kho tri thức trong RAG cũng vậy, nhỏ hơn LLM nhiều lần và chắc chắn là hữu hạn. Trong lúc đó, thế giới này không ngừng phát triển, phát sinh ra tri thức mới mỗi phút mỗi giây. Vì vậy, nếu RAG (và LLM) không nhận biết được rằng Response nằm ngoài hai kho tri thức này thì Response đó là ảo giác.
②
Chúng ta có cảm giác rằng lập một RAG Framework khá dễ dàng. Điều đó đúng nếu Kho tri thức chỉ gồm dăm ba tài liệu và các tài liệu này là tài liệu tĩnh, không biến thiên theo thời gian. Nhưng nếu Kho tri thức bao gồm hàng triệu, hàng tỷ tài liệu và chúng thay đổi theo thời gian thì vấn đề xây Kho tri thức rất thách thức:
- Tối ưu hóa Indexing và Embedding
- Hỗ trợ đa dạng các loại tài liệu như PDF, HTML, Word, …, tập hợp các bản ghi của nhiều CSDL quan hệ, …
- Cách tổ hợp câu truy vấn gốc với các tài liệu truy xuất để tạo ra đúng ngữ cảnh (Truy vấn tổ hợp với K documents)
- Giải pháp cho việc Kho tri thức thay đổi thường xuyên và lớn dần theo thời gian
- Giữ đồng bộ giữa tài liệu gốc và tài liệu Indexing
- Tuân thủ đúng chính sách bảo mật của tổ chức/doanh nghiệp sở hữu Kho tri thức
- Các vấn đề pháp lý, vấn đề an ninh an toàn dữ liệu, giải pháp bảo vệ tính riêng tư (Privacy) của dữ liệu trong môi trường điện toán đám mây (Cloud Computing)
~~~
Cuối cùng, tôi trân trọng mời anh/chị một tách cà phê mà trong tách cà phê đó có hai con tàu cướp biển đang chiến đấu với nhau (click để xem). Credit Sora (OpenAI).

